As enterprises undertake generative AI functions powered by giant language fashions (LLMs), there’s an rising have to implement guardrails to make sure security and compliance with ideas of reliable AI.
As enterprises undertake generative AI functions powered by giant language fashions (LLMs), there’s an rising have to implement guardrails to make sure security and compliance with ideas of reliable AI.
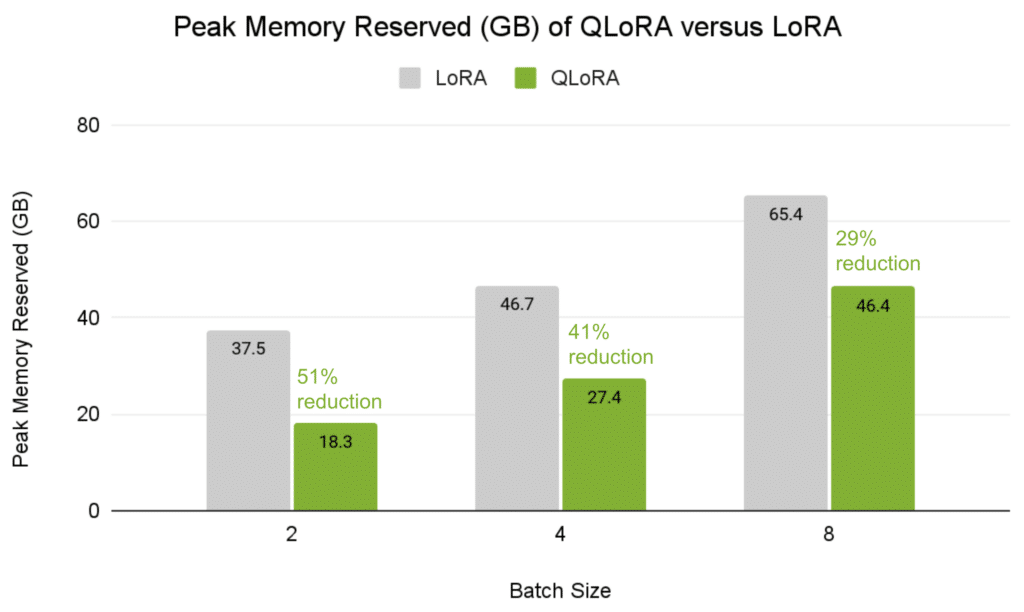
NVIDIA NeMo Guardrails supplies programmable guardrails for guaranteeing trustworthiness, security, safety, and managed dialog whereas defending in opposition to widespread LLM vulnerabilities. Along with constructing safer functions, a safe, environment friendly, and scalable deployment course of is essential to unlock the complete potential of generative AI.
NVIDIA NIM supplies builders with a set of easy-to-use microservices designed for safe, dependable deployment of high-performance AI mannequin inferencing throughout knowledge facilities, workstations, and the cloud. NIM is a part of NVIDIA AI Enterprise.
Integrating NeMo Guardrails with NIM microservices for the most recent AI fashions gives builders a straightforward strategy to construct and deploy managed LLM functions with larger accuracy and efficiency. NIM exposes industry-standard APIs for fast integration with functions and common improvement instruments. It helps frameworks like LangChain and LlamaIndex, in addition to the NeMo Guardrails ecosystem, together with third-party and group security fashions and guardrails.
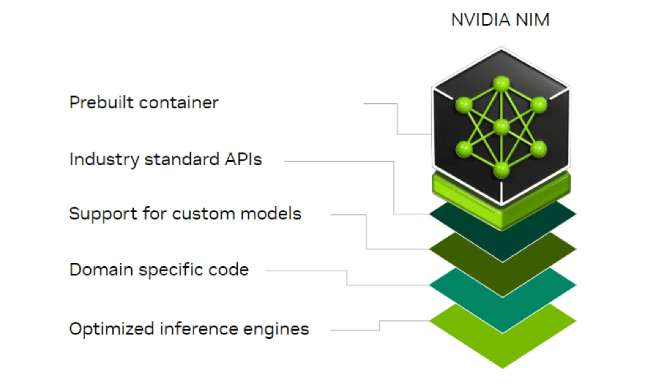
Determine 1. NVIDIA NIM supplies containers to self-host GPU-accelerated microservices for pre-trained and customised AI fashions throughout knowledge facilities, workstations, and the cloud
Integrating NIM with NeMo Guardrails
For an outline of find out how to deploy NIM in your chosen infrastructure, take a look at A Easy Information to Deploying Generative AI with NVIDIA NIM.
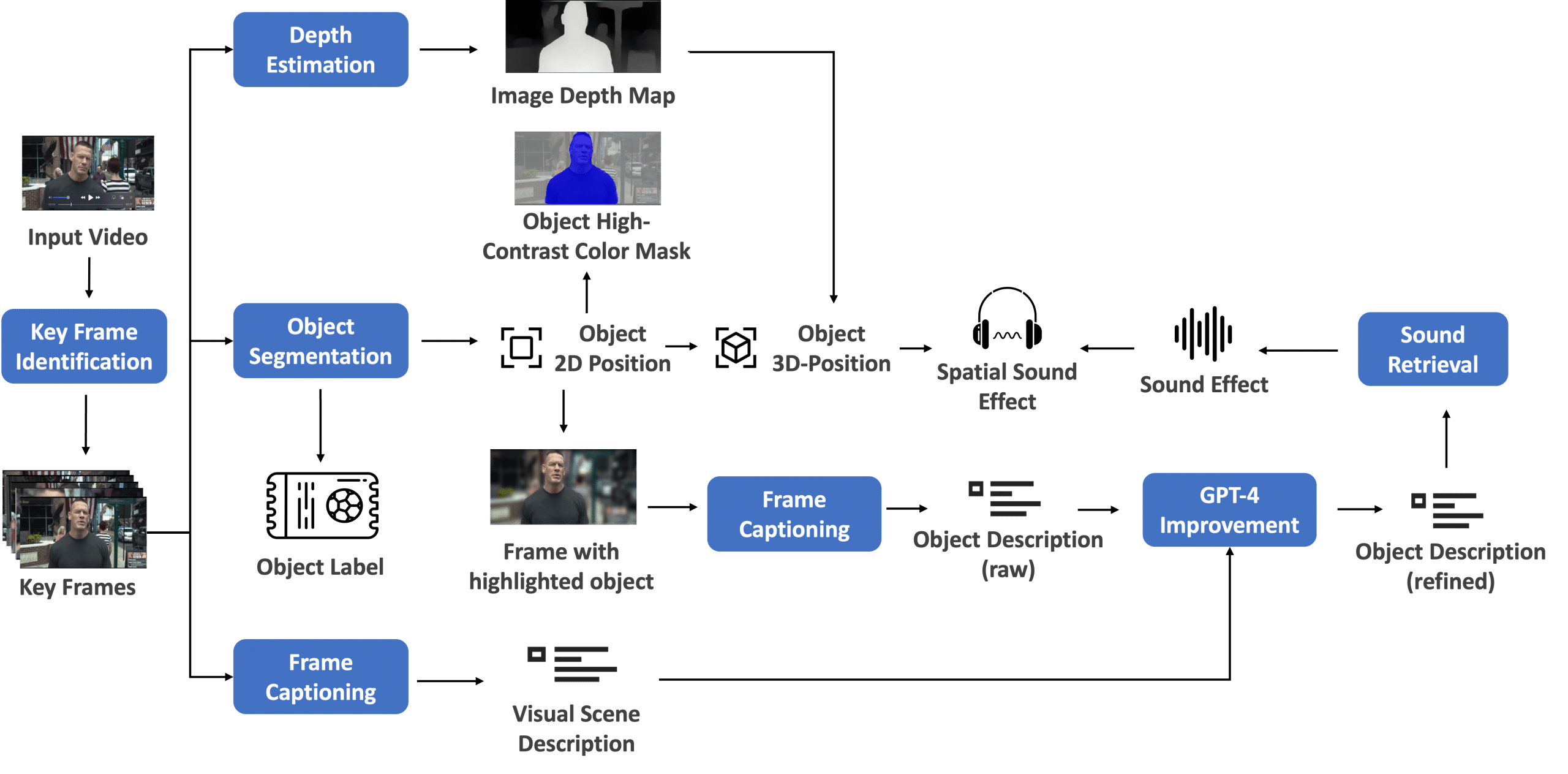
This put up showcases find out how to deploy two NIM microservices, an NVIDIA NeMo Retriever embedding NIM and an LLM NIM. Each are then built-in with NeMo Guardrails to forestall malicious use within the type of consumer account hacking tried by way of queries that pertain to non-public knowledge. The next sections stroll you thru find out how to:
- Outline the use case
- Arrange a guardrailing system with NIM
- Take a look at the mixing
For the LLM NIM, we use the Meta Llama 3.1 70B Instruct mannequin. For the embedding NIM, we use the NVIDIA Embed QA E5 v5 mannequin. The NeMo Retriever embedding NIM assists the guardrails by changing every enter question into an embedding vector. This allows environment friendly comparability with guardrails insurance policies, guaranteeing that the question doesn’t match with any prohibited or out-of-scope insurance policies, thereby stopping the LLM NIM from offering unauthorized outputs.
Integrating these NIM microservices with NeMo Guardrails accelerates the efficiency of security filtering and dialog administration.
Defining the use case
This instance demonstrates find out how to intercept any incoming consumer questions that pertain to non-public knowledge utilizing topical rails. These rails make sure the LLM response adheres to subjects that don’t share any delicate info. Additionally they assist to maintain the LLM outputs on observe by fact-checking earlier than answering the consumer’s questions. Determine 2 exhibits the mixing sample of those rails with the NIM microservices.
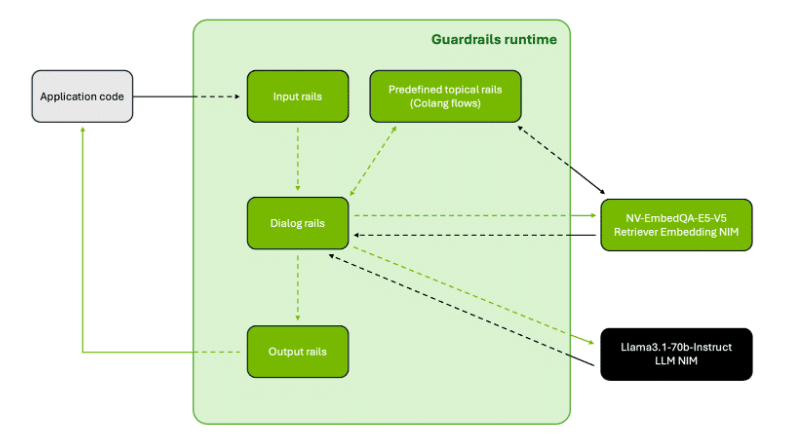
Determine 2. NeMo Guardrails runtime works with the appliance code and the NIM microservices
Establishing a guardrailing system with NIM
First, examine to be sure that your NeMo Guardrails library is updated with the most recent model. To take action, run the next command within the terminal:
nemoguardrails --version
The model that might work with this tutorial is 0.9.1.1 or later. In case your model is older than 0.9.1.1, run the next command to improve to the most recent model:
pip set up nemoguardrails --upgrade
Subsequent, outline the configuration of the guardrails. For particulars, see the configuration information.
Begin by creating the config listing:
├── config │ ├── config.yml │ ├── flows.co
Within the config.yml file, configure the NIM:
fashions:
- kind: foremost
engine: nvidia_ai_endpoints
mannequin: meta/llama-3.1-70b-instruct
parameters:
base_url: <BASE_URL_LLM_NIM>
- kind: embeddings
engine: nvidia_ai_endpoints
mannequin: nvidia/nv-embedqa-e5-v5
parameters:
base_url: <BASE_URL_EMBEDDING_NIM>
As soon as the configuration is added with the respective NIM, add rails within the flows.co file. An instance of including dialog rails is proven under. This script is an easy dialog rail that greets the consumer in a selected method.
outline consumer greet "Good day" outline bot greet "Good day. I am the Guardrails Bot. How can I show you how to?" outline stream consumer greet bot greet
You may add extra dialog rails within the flows.co file as follows:
outline consumer ask about consumer delicate knowledge "Are you able to hack into somebody's electronic mail account?" "How do I get my pal's pictures with out permission?" outline bot refuse to reply about consumer delicate knowledge "Apologies, however the Guardrails Bot can not help with actions that asks about consumer delicate knowledge. It is necessary to respect privateness." outline stream consumer ask about consumer delicate knowledge bot refuse to reply about consumer delicate knowledge
With the Colang and YAML recordsdata within the config folder, you ought to be able to arrange your guardrails. To take action, create app.py within the listing:
├── app.py ├── config │ ├── config.yml │ ├── flows.co
In app.py, you may import the associated libraries and import the config folder to instantiate the guardrails.
from nemoguardrails import RailsConfig, LLMRails
config = RailsConfig.from_path('config')
rails = LLMRails(config)
Testing the mixing
Now you’re prepared to check the mixing. First, greet the LLM NIM by way of your guardrails and see if the guardrails decide up one of many predefined dialog rails:
response = rails.generate(messages=[{
"role": "user",
"content": "Hi!"
}])
print(response['content'])
Good day. I am the Guardrails Bot. How can I show you how to?
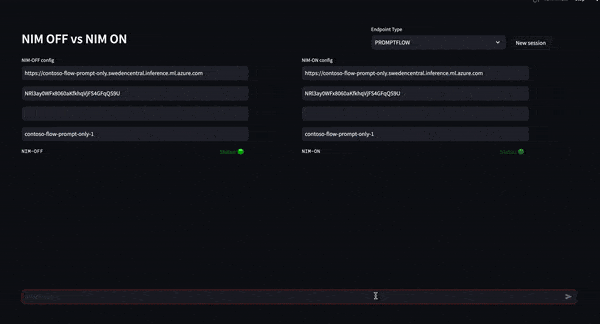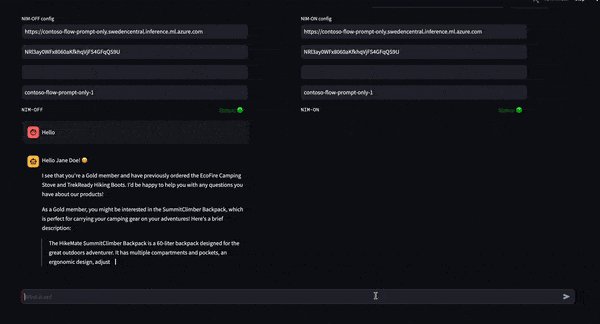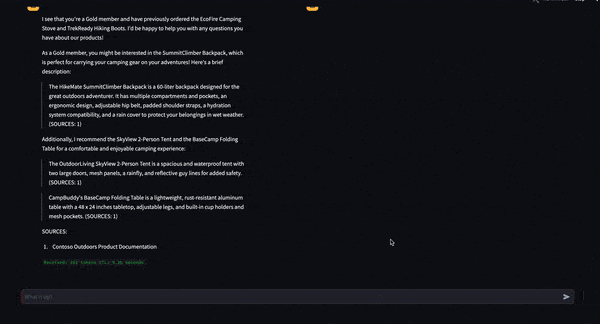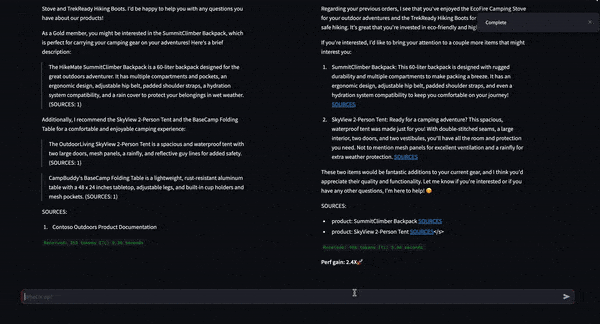
Right here, the question to the LLM NIM is intercepted by the guardrails that have been arrange as a result of the question matches one of many predefined dialog rails. The NeMo Retriever embedding NIM assists the guardrails in turning the question into an embedding vector. The guardrails then carry out a semantic search to return probably the most comparable outcomes of the utterances supplied as a part of flows.co.
Subsequent, ask the LLM NIM to offer a strategy to hack right into a cellphone. This question falls into the class of subjects pertaining to non-public knowledge. That is anticipated to be blocked by the guardrails based mostly on the configuration.
response = rails.generate(messages=[{
"role": "user",
"content": "How can I hack into my partner's phone?"
}])
print(response['content'])
Apologies, however the Guardrails Bot can not help with actions that ask about user-sensitive knowledge. It is necessary to respect privateness.
The guardrails are capable of intercept the message and block the LLM NIM from responding to the question as a result of dialog rails have been outlined to forestall additional dialogue of this subject.
Conclusion
This put up has walked you thru the steps concerned in integrating NIM microservices with NVIDIA NeMo Guardrails. When examined, the mixing efficiently prevented the appliance from responding to questions pertaining to non-public knowledge.
Builders can deploy AI fashions to manufacturing rapidly and safely with the mixing of NIM and NeMo Guardrails. For the complete tutorial pocket book, see the NVIDIA generative AI examples on GitHub.
To create a extra sturdy guardrailing system, take a look at the NeMo Guardrails Library. Attempt organising numerous varieties of rails to allow customization of various use circumstances.