 The open-source llama.cpp code base was initially launched in 2023 as a light-weight however environment friendly framework for performing inference on Meta Llama fashions. Constructed on the GGML library launched the earlier yr, llama.cpp shortly grew to become enticing to many customers and builders (significantly to be used on private workstations) because of its give attention to C/C++ with out the necessity for complicated dependencies.
The open-source llama.cpp code base was initially launched in 2023 as a light-weight however environment friendly framework for performing inference on Meta Llama fashions. Constructed on the GGML library launched the earlier yr, llama.cpp shortly grew to become enticing to many customers and builders (significantly to be used on private workstations) because of its give attention to C/C++ with out the necessity for complicated dependencies.
Since preliminary launch, llama.cpp has been prolonged to help not solely a variety of fashions, quantization, and extra, but in addition a number of backends together with NVIDIA CUDA-enabled GPUs. On the time of writing, llama.cpp sits at #123 within the star rating of all GitHub repos, and #11 of all C++ GitHub repos.
Performing AI inference with llama.cpp on NVIDIA GPUs already presents vital advantages, because of their skill to carry out the computations underlying AI inference with excessive efficiency and power effectivity, paired with their prevalence in client gadgets and knowledge facilities. NVIDIA and the llama.cpp developer group proceed to collaborate to additional improve efficiency. This submit describes latest enhancements achieved by means of introducing CUDA graph performance to llama.cpp.
CUDA Graphs
GPUs proceed to hurry up with every new era, and it’s usually the case that every exercise on the GPU (resembling a kernel or reminiscence copy) completes in a short time. Up to now, every exercise needed to be individually scheduled (launched) by the CPU, and related overheads may accumulate to turn into a efficiency bottleneck.
The CUDA Graphs facility addresses this drawback by enabling a number of GPU actions to be scheduled as a single computational graph. In a earlier submit, Getting Began with CUDA Graphs, I introduce CUDA Graphs and display learn how to get began. In a subsequent submit, A Information to CUDA Graphs in GROMACS 2023, I describe how CUDA Graphs had been efficiently utilized to the GROMACS biomolecular simulation scientific software program bundle.
When utilizing the standard stream mannequin, every GPU exercise is scheduled individually, whereas CUDA graphs allow a number of GPU actions to be scheduled in unison. This reduces scheduling overheads. It’s comparatively easy to adapt an current stream-based code to make use of graphs. The performance “captures” the stream execution right into a graph, by means of a couple of additional CUDA API calls.
This submit explains learn how to exploit this facility to allow the pre-existing llama.cpp code to be executed utilizing graphs as a substitute of streams.
Implementing CUDA Graphs in llama.cpp
This part highlights the overheads within the pre-existing code, and describes how CUDA Graphs have been launched to scale back these overheads.
Overheads in pre-existing code
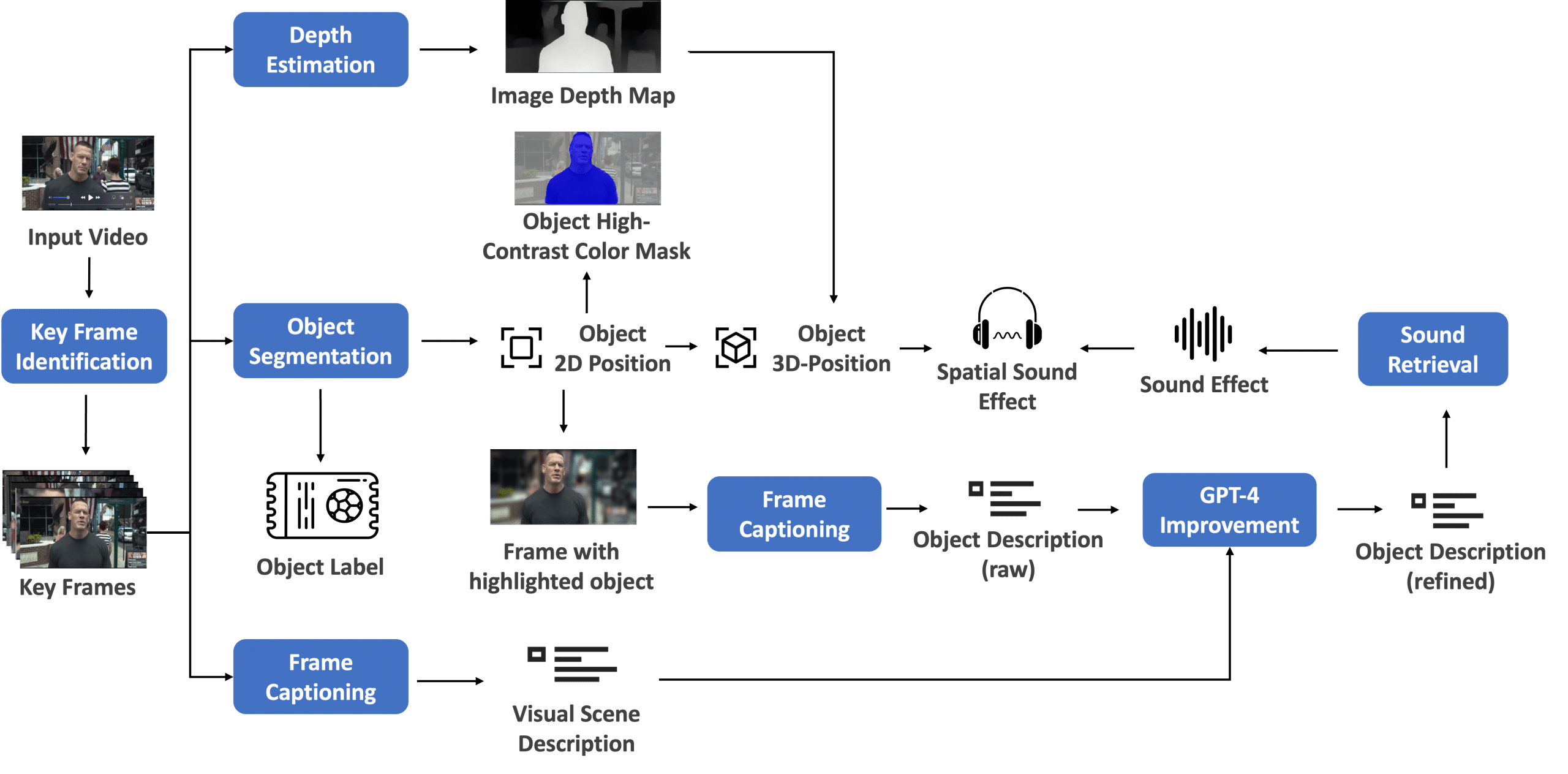
Determine 1 exhibits snippets of the profile of the pre-existing code, earlier than the introduction of CUDA Graphs, performing Llama 7B This autumn inference on an NVIDIA A100 GPU utilizing Linux. It was obtained utilizing NVIDIA Nsight Programs. Every chunk of GPU actions within the high profile within the determine corresponds to the analysis of a single token, the place the zoom is about to point out two full tokens being evaluated. It may be seen that there are gaps within the profile between the analysis of every token, equivalent to CPU actions associated to sampling and preparation of the compute graph. (I’ll return so far on the finish of the submit.)
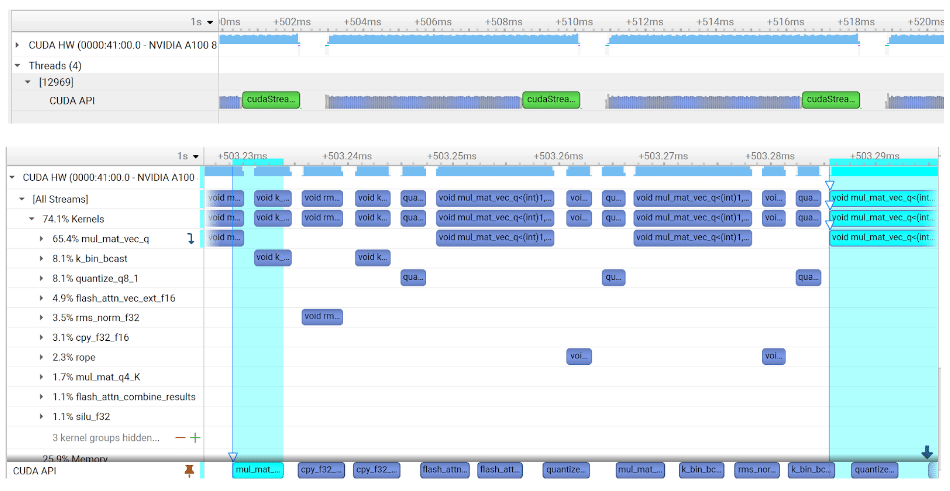
Determine 1. Overheads related to the GPU actions concerned in GPU inference, noticed by means of sections of the profiling timeline the place the GPU is idle
The underside of Determine 1 exhibits the identical profile however zoomed in to point out a number of actions inside the analysis of a token. The gaps seen between kernels inside token analysis are because of launch overheads. As this submit will present, the removing of those overheads with CUDA Graphs results in substantial efficiency enchancment. The highlighted occasions are the launch of a kernel from the CPU (backside left) and the corresponding kernel execution on the GPU (high proper): the CPU is ready to efficiently launch properly prematurely of execution on the GPU.
Due to this fact, CPU-side launch overheads should not on important path right here. As a substitute, the overheads are because of GPU-side actions related to every kernel launch. This conduct could fluctuate throughout totally different fashions and {hardware}, however CUDA Graphs are relevant for lowering CPU and/or GPU launch overheads.
Introducing CUDA Graphs to scale back overheads
llama.cpp already makes use of the idea of a “graph” in GGML format. The era of every token includes the next steps:
- Preparation of the GGML graph construction primarily based on the mannequin in use.
- Analysis of the construction on the backend in use (on this case an NVIDIA GPU) to get “logits,” log likelihood distribution throughout vocabulary for subsequent token.
- Sampling is carried out on the CPU to pick out a token from the vocabulary utilizing the logits.
CUDA Graphs had been launched by intercepting the GPU graph analysis stage. Code was added to seize the present stream right into a graph, instantiate the captured graph into an executable graph, and launch that to the GPU to carry out the analysis of a single token.
To be suitably environment friendly, it’s essential to re-use the identical graph a number of occasions; in any other case, newly launched overheads concerned in seize and instantiation outweigh the advantages. Nonetheless, the graph dynamically evolves as inference proceeds. The problem was to develop a mechanism to allow minor (low-overhead) changes to the graph throughout tokens, to succeed in an general profit.
As inference progresses, the size of operations steps up with context measurement, leading to substantial (however rare) adjustments to the compute graph. The GGML graph is inspected and solely recaptured when required. cudaGraphExecUpdate is used to replace the beforehand instantiated executable graph with a lot decrease overhead than full re-instantiation.
There are additionally frequent, however very minor, adjustments to the compute graph, the place kernel parameters for sure nodes (associated to the KV cache) change for every token. NVIDIA developed a mechanism to replace solely these parameters in a re-usable CUDA Graph. Earlier than every graph is launched, we leverage CUDA Graph API performance to establish the a part of the graph that requires updating, and to manually change the related parameters.
Word that CUDA Graphs are presently restricted to batch measurement 1 inference (a key use case for llama.cpp) with additional work deliberate on bigger batch sizes. For extra data on these developments and ongoing work to handle points and restrictions, see the GitHub situation, new optimization from NVIDIA to make use of CUDA Graphs in llama.cpp, and pull requests linked therein.
Influence of CUDA Graphs in lowering overheads
Earlier than the introduction of CUDA Graphs there existed vital gaps between kernels because of GPU-side launch overhead, as proven within the backside profile in Determine 1.
Determine 2 exhibits the equal with CUDA Graphs. All of the kernels are submitted to the GPU as a part of the identical computational graph (with a single CUDA API launch name). This vastly reduces the overheads: the hole between every kernel inside the graph is now very small.
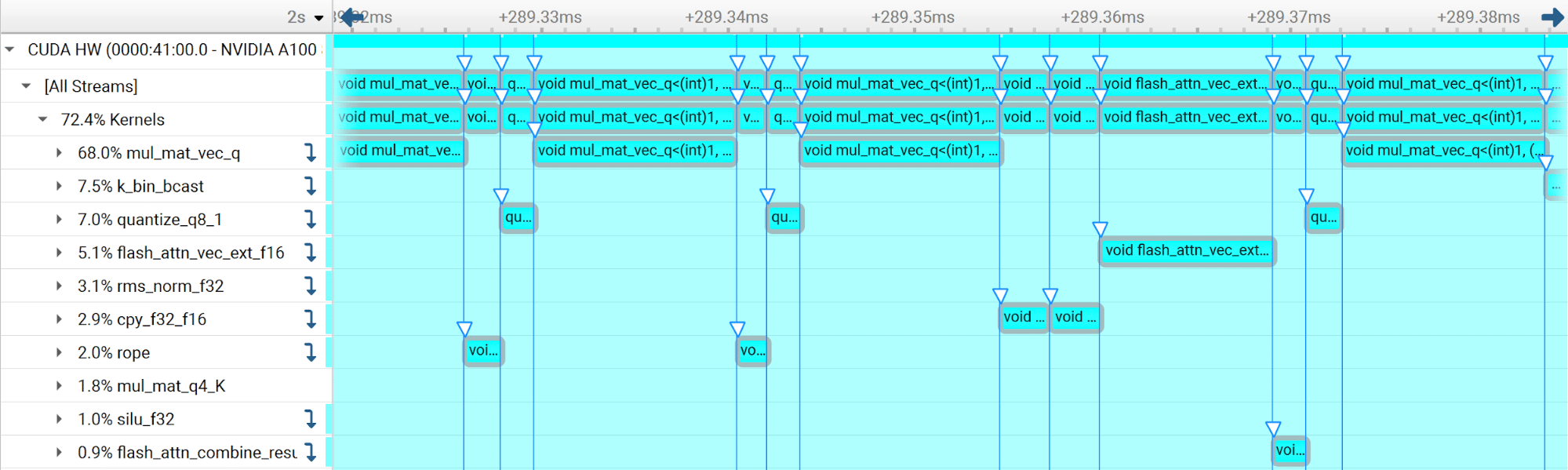
Determine 2. Overheads related to the GPU actions concerned in GPU inference are vastly decreased with CUDA Graphs
Efficiency outcomes
Determine 3 exhibits the advantage of the brand new CUDA Graphs performance in llama.cpp. The measured speedup varies throughout mannequin sizes and GPU variants, with growing advantages as mannequin measurement decreases and GPU functionality will increase. That is in keeping with expectations, as utilizing CUDA Graphs reduces the overheads most related for small issues on quick GPUs. The very best achieved speedup is 1.2x for the smallest Llama 7B mannequin on the quickest NVIDIA H100 GPUs. Linux methods had been used for all outcomes.
CUDA Graphs at the moment are enabled by default for batch measurement 1 inference on NVIDIA GPUs in the primary department of llama.cpp.
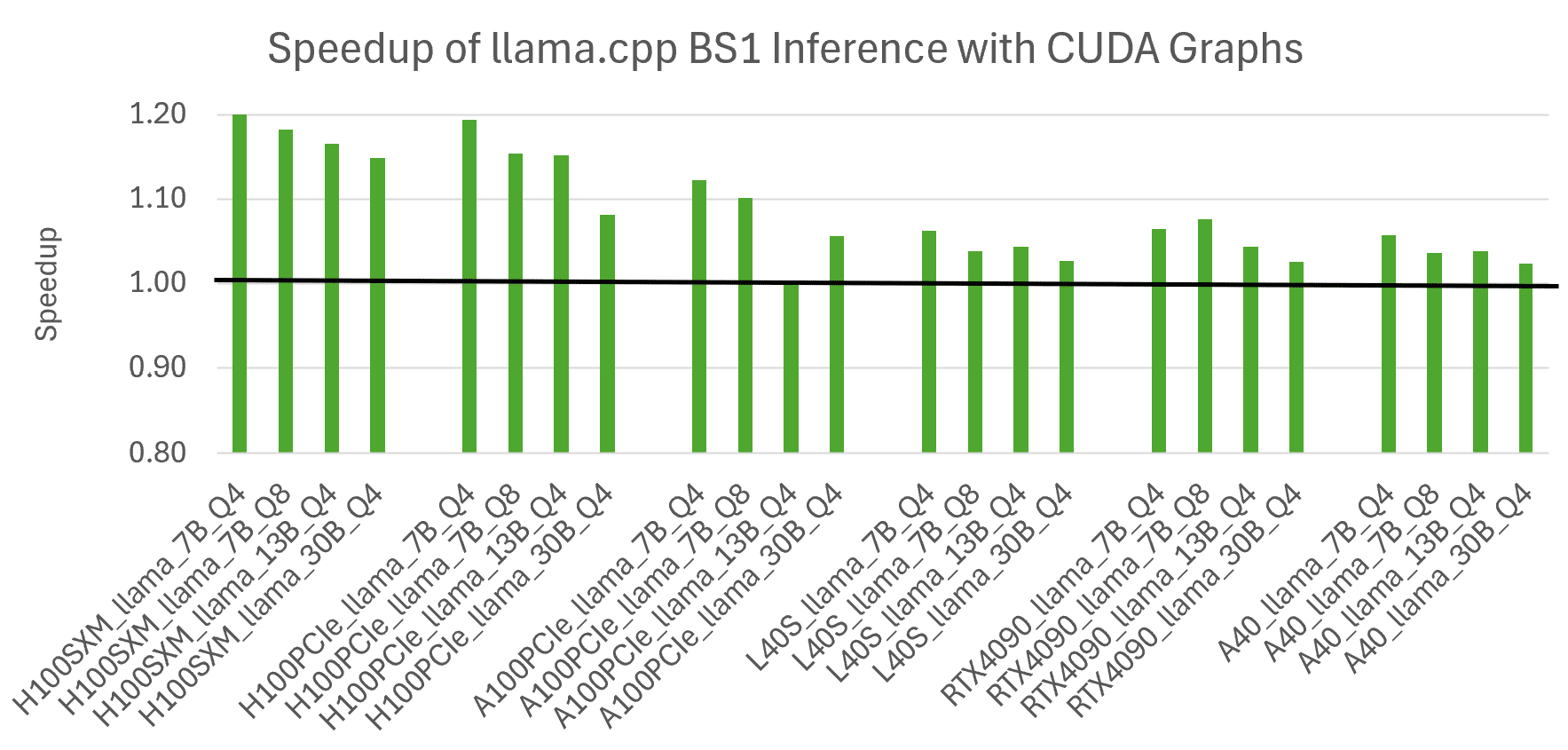
Determine 3. The speedup achieved with CUDA Graphs towards conventional streams, for a number of Llama fashions of various sizes (all with batch measurement 1), together with outcomes throughout a number of variants of NVIDIA GPUs
Ongoing work to scale back CPU overheads
The highest profile in Determine 1 exhibits gaps (the place the GPU is idle) between token analysis within the timeline. These are because of CPU actions related to preparation of the GGML graph and with sampling. Work to scale back these overheads is at a complicated stage, as described on this GitHub situation and the pull requests linked therein. This work is predicted to supply as much as ~10% additional enchancment.
Abstract
On this submit, I confirmed how the introduction of CUDA Graphs to the favored llama.cpp code base has considerably improved AI inference efficiency on NVIDIA GPUs, with ongoing work promising additional enhancements. To make the most of this work to your personal AI-enabled workflow, comply with the Utilization Directions.