Massive language fashions (LLM) are actually a dominant pressure in pure language processing and understanding, because of their effectiveness and flexibility. LLMs corresponding to Llama 3.1 405B and NVIDIA Nemotron-4 340B excel in lots of difficult duties, together with coding, reasoning, and math. They’re, nonetheless, resource-intensive to deploy. As such, there’s one other development within the business to develop small language fashions (SLMs), that are sufficiently proficient in lots of language duties however less expensive to deploy to the plenty.
Massive language fashions (LLM) are actually a dominant pressure in pure language processing and understanding, because of their effectiveness and flexibility. LLMs corresponding to Llama 3.1 405B and NVIDIA Nemotron-4 340B excel in lots of difficult duties, together with coding, reasoning, and math. They’re, nonetheless, resource-intensive to deploy. As such, there’s one other development within the business to develop small language fashions (SLMs), that are sufficiently proficient in lots of language duties however less expensive to deploy to the plenty.
Lately, NVIDIA researchers confirmed that structured weight pruning mixed with data distillation kinds an efficient and environment friendly technique for acquiring progressively smaller language fashions from an preliminary bigger sibling. NVIDIA Minitron 8B and 4B are such small fashions, obtained by pruning and distilling their bigger 15B sibling within the NVIDIA Nemotron household.
Pruning and distillation result in a number of advantages:
- Enchancment in MMLU scores by 16% in comparison with coaching from scratch.
- Fewer coaching tokens are required for every further mannequin, ~100B tokens with an as much as 40x discount.
- Compute value saving to coach a household of fashions, as much as 1.8x in comparison with coaching all fashions from scratch.
- Efficiency is akin to Mistral 7B, Gemma 7B, and Llama-3 8B educated on many extra tokens, as much as 15T.
The paper additionally presents a set of sensible and efficient structured compression finest practices for LLMs that mix depth, width, consideration, and MLP pruning with data distillation-based retraining.
On this publish, we first talk about these finest practices after which present their effectiveness when utilized to the Llama 3.1 8B mannequin to acquire a Llama-3.1-Minitron 4B mannequin. Llama-3.1-Minitron 4B performs favorably in opposition to state-of-the-art open-source fashions of comparable dimension, together with Minitron 4B, Phi-2 2.7B, Gemma2 2.6B, and Qwen2-1.5B. Llama-3.1-Minitron 4B can be launched to the NVIDIA HuggingFace assortment quickly, pending approvals.
Pruning and distillation
Pruning is the method of constructing the mannequin smaller and leaner, both by dropping layers (depth pruning) or dropping neurons and a focus heads and embedding channels (width pruning). Pruning is usually accompanied by some quantity of retraining for accuracy restoration.
Mannequin distillation is a method used to switch data from a big, complicated mannequin, usually referred to as the instructor mannequin, to a smaller, easier scholar mannequin. The objective is to create a extra environment friendly mannequin that retains a lot of the predictive energy of the unique, bigger mannequin whereas being sooner and fewer resource-intensive to run.
Classical data distillation vs. SDG finetuning
There are two essential kinds of distillation:
- SDG finetuning: The artificial knowledge generated from a bigger instructor mannequin is used to additional fine-tune a smaller, pretrained scholar mannequin. Right here, the scholar mimics solely the ultimate token predicted by the instructor. That is exemplified by the Llama 3.1 Azure Distillation in Azure AI Studio and AWS Use Llama 3.1 405B for artificial knowledge technology and distillation to fine-tune smaller fashions tutorials.
- Classical data distillation: The coed mimics the logits and different intermediate states of the instructor on the coaching dataset quite than simply studying the token that must be predicted. This may be considered as offering higher labels (a distribution in comparison with a one-shot label). Even with the identical knowledge, the gradient accommodates richer suggestions, bettering the coaching accuracy and effectivity. Nevertheless, there should be coaching framework help for this model of distillation because the logits are too giant to retailer.
These two kinds of distillation are complementary to 1 one other, quite than mutually unique. This publish primarily focuses on the classical data distillation strategy.
Pruning and distillation process
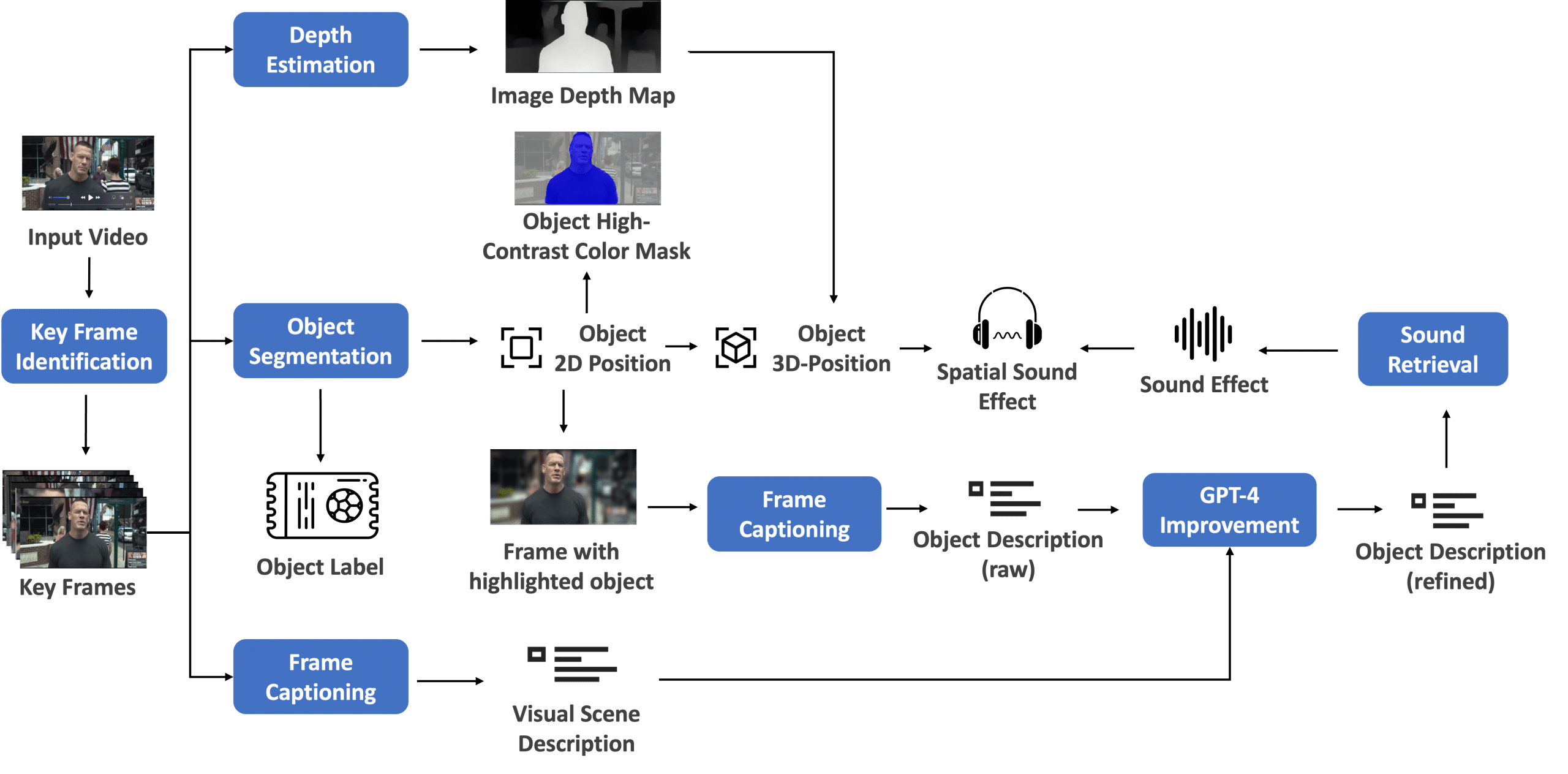
We proposed combining pruning with classical data distillation as a resource-efficient retraining method (Determine 1).
- We began from a 15B mannequin. We estimated the significance of every part (layer, neuron, head, and embedding channel) after which ranked and trimmed the mannequin to the goal dimension: an 8B mannequin.
- We carried out a light-weight retraining process utilizing mannequin distillation with the unique mannequin because the instructor and the pruned mannequin as the scholar.
- After coaching, the small mannequin (8B) served as a place to begin to trim and distill to a smaller 4B mannequin.
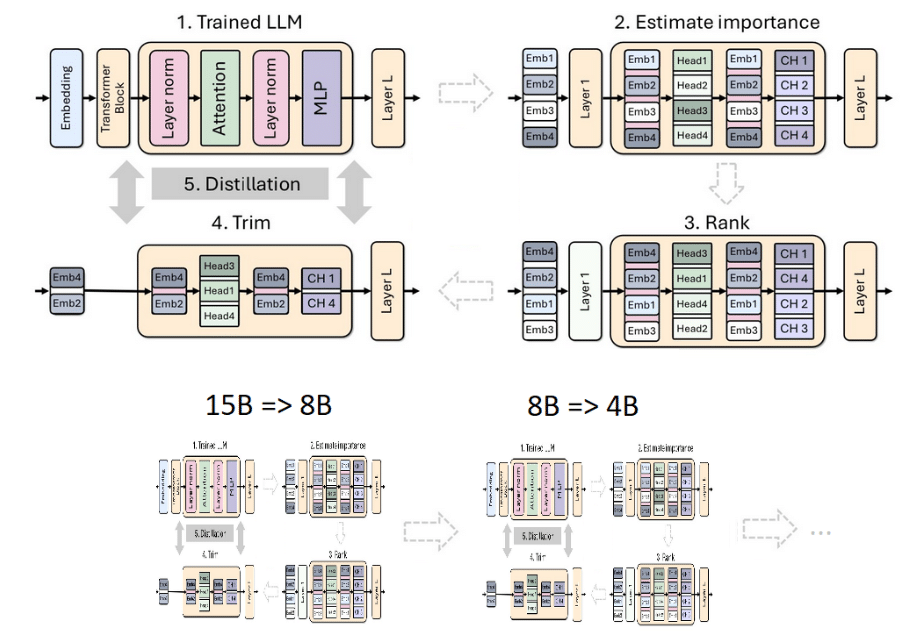
Determine 1. Iterative mannequin pruning and distillation process
Determine 1 exhibits the pruning and distillation strategy of a single mannequin (high) and the chain of mannequin pruning and distillation (backside). Within the latter, the output mannequin of a earlier stage serves because the enter mannequin for the subsequent stage.
Significance evaluation
To prune a mannequin, it’s important to know which elements of the mannequin are necessary. We suggest utilizing a purely activation-based significance estimation technique that concurrently computes sensitivity data for all of the axes thought-about (depth, neuron, head, and embedding channel) utilizing a small (1024 samples) calibration dataset and solely ahead propagation passes. This technique is extra simple and cost-effective to implement in comparison with methods that depend on gradient data and require a backward propagation go.
Whereas pruning, you’ll be able to iteratively alternate between pruning and significance estimation for a given axis or mixture of axes. Nevertheless, our empirical work exhibits that it’s enough to make use of single-shot significance estimation and iterative estimation supplies no profit.
Retraining with classical data distillation
Determine 2 exhibits the distillation course of with a scholar mannequin (pruned mannequin) with N layers distilled from a instructor mannequin (unique unpruned mannequin) with M layers. The coed learns by minimizing a mixture of embedding output loss, logit loss, and transformer encoder-specific losses mapped throughout scholar block S and instructor block T.
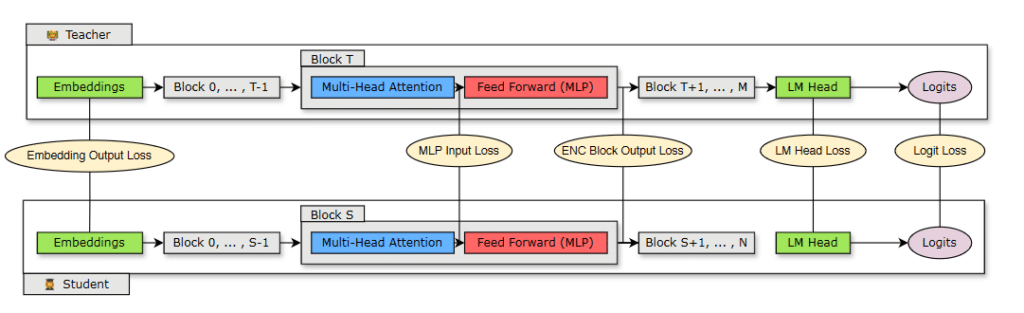
Determine 2. Distillation coaching losses
Pruning and distillation finest practices
Primarily based on the intensive ablation research carried out in Compact Language Fashions by way of Pruning and Data Distillation, we summarized our learnings into a number of structured compression finest practices:
- Sizing:
- To coach a household of LLMs, first prepare the most important one, then prune and distill iteratively to acquire smaller LLMs.
- If the most important mannequin is educated utilizing a multi-phase coaching technique, it’s best to prune and retrain the mannequin obtained from the ultimate stage of coaching.
- Prune an obtainable supply mannequin closest to the goal dimension.
- Pruning:
- Want width over depth pruning. This labored effectively for the mannequin scales thought-about (≤ 15B).
- Use single-shot significance estimation. Iterative significance estimation offered no profit.
- Retraining:
- Retrain solely with distillation loss as an alternative of typical coaching.
- Use logit plus intermediate state plus embedding distillation when the depth is lowered considerably.
- Use logit-only distillation when depth isn’t lowered considerably.
Llama-3.1-Minitron: placing finest practices to work
Meta just lately launched the highly effective Llama 3.1 mannequin household, a primary wave of open-source fashions which might be comparable with closed-source fashions throughout many benchmarks. Llama 3.1 ranges from the large 405B mannequin to the 70B and 8B.
Geared up with expertise of Nemotron distillation, we got down to distill the Llama 3.1 8B mannequin to a smaller and extra environment friendly 4B sibling:
- Instructor fine-tuning
- Depth-only pruning
- Width-only pruning
- Accuracy benchmarks
- Efficiency benchmarks
Instructor fine-tuning
To appropriate for the distribution shift throughout the unique dataset the mannequin was educated on, we first fine-tuned the unpruned 8B mannequin on our dataset (94B tokens). Experiments confirmed that, with out correcting for the distribution shift, the instructor supplies suboptimal steering on the dataset when being distilled.
Depth-only pruning
To go from an 8B to a 4B, we pruned 16 layers (50%). We first evaluated the significance of every layer or steady subgroup of layers by dropping them from the mannequin and observing the rise in LM loss or accuracy discount on a downstream process.
Determine 5 exhibits the LM loss worth on the validation set after eradicating 1, 2, 8, or 16 layers. For instance, the purple plot at layer 16 signifies the LM loss if we dropped the primary 16 layers. Layer 17 signifies the LM loss if we depart the primary layer and drop layers 2 to 17. We noticed that the layers firstly and finish are a very powerful.
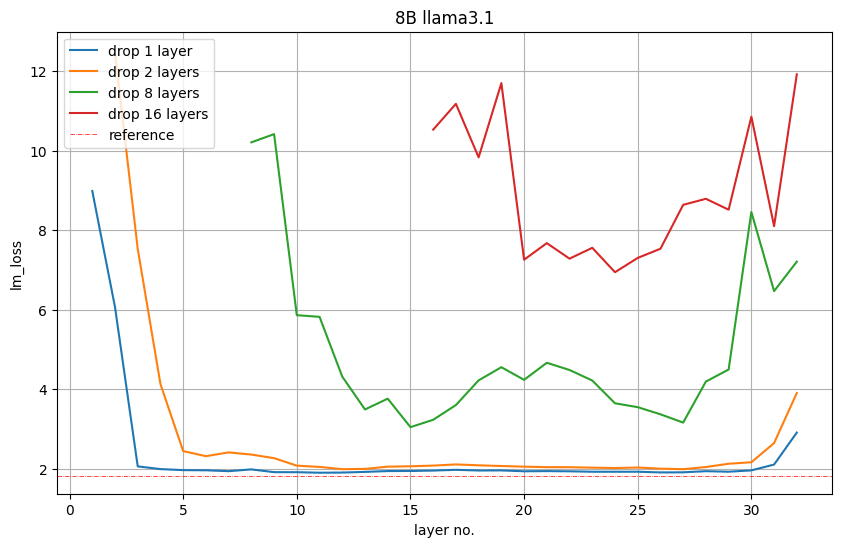
Determine 5. Layer significance in depth-only pruning
Nevertheless, we noticed that this LM loss just isn’t essentially straight correlated with downstream efficiency.
Determine 6 exhibits the Winogrande accuracy for every pruned mannequin. It signifies that it’s best to take away layers 16 to 31, with 31 being the second-to-last layer, the place the pruned mannequin 5-shot accuracy is considerably higher than random (0.5). We adopted this perception and eliminated layers 16 to 31.
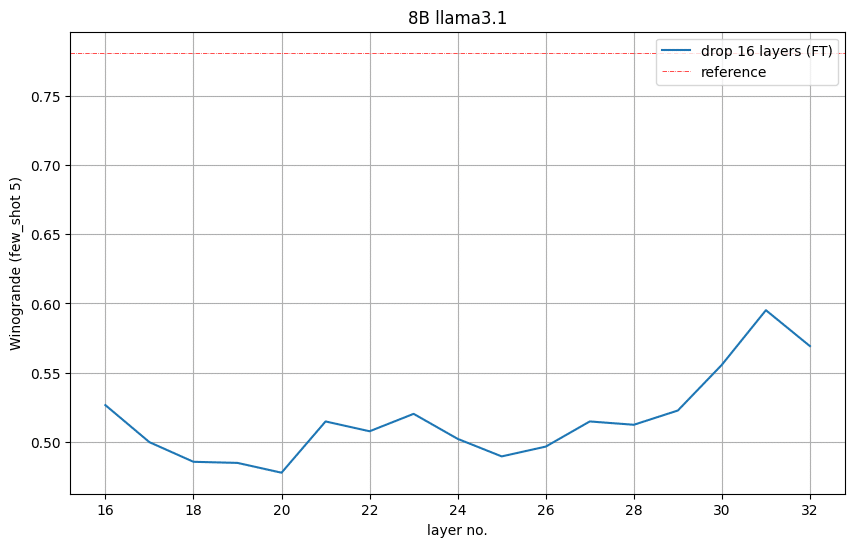
Determine 6. Accuracy on the Winogrande process when eradicating 16 layers
Width-only pruning
We pruned each the embedding (hidden) and MLP intermediate dimensions alongside the width axis to compress Llama 3.1 8B. Particularly, we computed significance scores for every consideration head, embedding channel, and MLP hidden dimension utilizing the activation-based technique described earlier. Following significance estimation, we:
- Pruned (trim) the MLP intermediate dimension from 14336 to 9216.
- Pruned the hidden dimension from 4096 to 3072.
- Retrained the eye headcount and variety of layers.
It’s price mentioning that instantly after one-shot pruning, the LM lack of width pruning is larger than that of depth pruning. Nevertheless, after a brief retraining, the development reverses.
Accuracy benchmarks
We distilled the mannequin with the next parameters:
- Peak studying price=1e-4
- Minimal studying price=1e-5
- Linear warm-up of 40 steps
- Cosine decay schedule
- International batch dimension=1152
Desk 1 exhibits the comparative efficiency of Llama-3.1-Minitron 4B mannequin variants (width-pruned and depth-pruned) compared with the unique Llama 3.1 8B fashions and different fashions of comparable dimension on benchmarks spanning a number of domains.
Total, we reconfirmed the effectiveness of a width-pruning technique in comparison with depth pruning, which follows the most effective practices.
Benchmark
No. of pictures
Metric
Llama-3.1 8B
Minitron 4B
Llama-3.1-Minitron 4B
Phi-2 2.7B
Gemma2 2.6B
†
Qwen2-1.5B
†
Width-pruned
Depth-pruned
Width-pruned winogrande 5 acc 0.7727 0.7403* 0.7214 0.7348 0.7400** 0.709 0.662 arc_challenge 25 acc_norm 0.5794 0.5085 0.5256 0.5555** 0.6100* 0.554 0.439 MMLU 5 acc 0.6528 0.5860** 0.5871 0.6053* 0.5749 0.513 0.565 hellaswag 10 acc_norm 0.8180 0.7496 0.7321 0.7606* 0.7524** 0.73 0.666 gsm8k 5 acc 0.4860 0.2411 0.1676 0.4124 0.5500** 0.239 0.585* truthfulqa 0 mc2 0.4506 0.4288 0.3817 0.4289 0.4400** – 0.459* XLSum en (20%) 3 rougeL 0.3005 0.2954* 0.2722 0.2867** 0.0100 – – MBPP 0 go@1 0.4227 0.2817 0.3067 0.324 0.4700* 0.29 0.374**
Coaching Tokens 15T 94B 1.4T 3T 7T
Desk 1. Accuracy of Minitron 4B base fashions in comparison with equally sized base group fashions
* Greatest mannequin
** Second-best mannequin
– Unavailable outcomes
† Outcomes as reported within the mannequin report by the mannequin writer.
To confirm that the distilled fashions could be sturdy instruct fashions, we fine-tuned the Llama-3.1-Minitron 4B fashions utilizing NeMo-Aligner. We used coaching knowledge used for Nemotron-4 340B and evaluated the fashions on IFEval, MT-Bench, ChatRAG-Bench, and Berkeley Perform Calling Leaderboard (BFCL) to check instruction-following, roleplay, RAG, and function-calling capabilities. We confirmed that Llama-3.1-Minitron 4B fashions could be stable instruct fashions, which outperform different baseline SLMs (Desk 2).
Minitron 4B
Llama-3.1-Minitron 4B
Gemma 2B
Phi-2 2.7B
Gemma2 2.6B
Qwen2-1.5B
Benchmark Width-pruned Depth-pruned Width-pruned
IFEval 0.4484 0.4257 0.5239** 0.4050 0.4400 0.6451* 0.3981
MT-Bench 5.61 5.64 6.34** 5.19 4.29 7.73* 5.22
ChatRAG
† 0.4111** 0.4013 0.4399* 0.3331 0.3760 0.3745 0.2908
BFCL 0.6423 0.6680* 0.6493** 0.4700 0.2305 0.3562 0.3275
Coaching Tokens 94B 3T 1.4T 2T 7T
Desk 2. Accuracy of aligned Minitron 4B base fashions in comparison with equally sized aligned group fashions
* Greatest mannequin
** Second-best mannequin
† Primarily based on a consultant subset of ChatRAG, not the entire benchmark.
Efficiency benchmarks
We optimized the Llama 3.1 8B and Llama-3.1-Minitron 4B fashions with NVIDIA
TensorRT-LLM, an open-source toolkit for optimized LLM inference.
Figures 7 and eight present the throughput requests per second of various fashions in FP8 and FP16 precision on completely different use instances, represented as enter sequence size/output sequence size (ISL/OSL) combos at batch dimension 32 for the 8B mannequin and batch dimension 64 for the 4B fashions, because of the smaller weights permitting for bigger batches, on one NVIDIA H100 80GB GPU.
The Llama-3.1-Minitron-4B-Depth-Base variant is the quickest, at a mean of ~2.7x throughput of Llama 3.1 8B, whereas the Llama-3.1-Minitron-4B-Width-Base variant is at a mean of ~1.8x throughput of Llama 3.1 8B. Deployment in FP8 additionally delivers a efficiency enhance of ~1.3x throughout all three fashions in comparison with BF16.
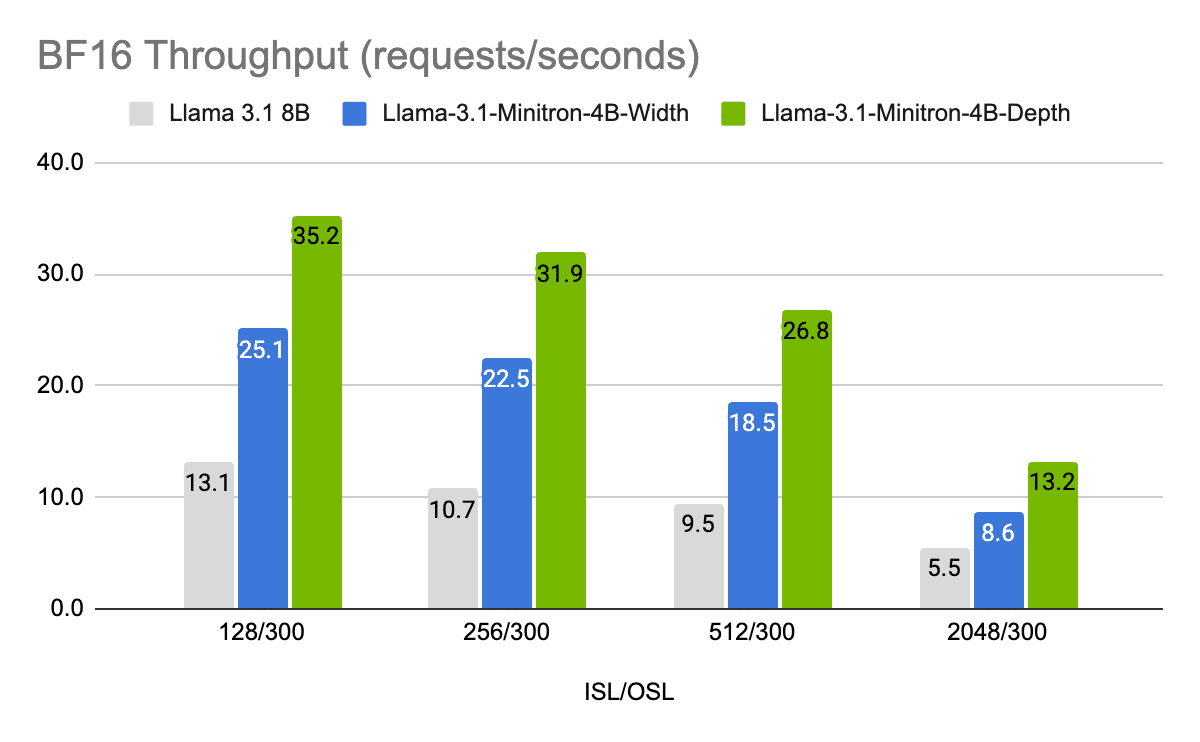
Determine 7. Efficiency benchmarks for request BF16 throughput at completely different enter/output size combos
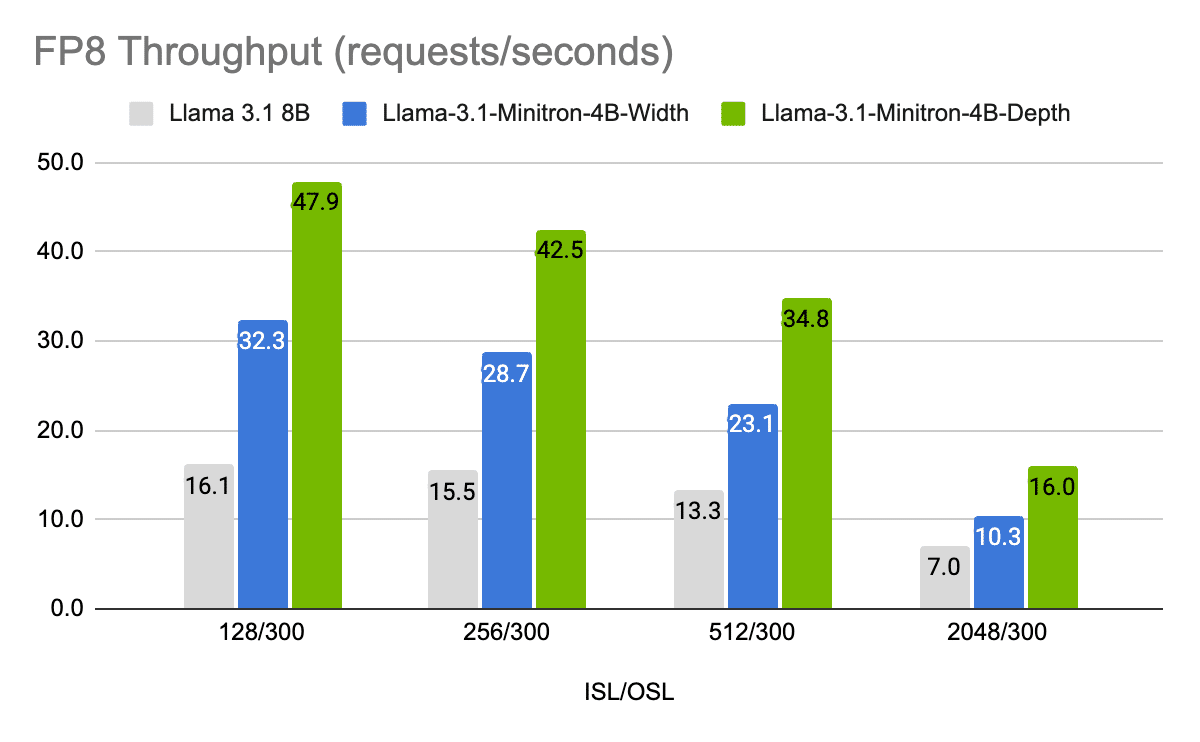
Determine 8. Efficiency benchmarks for request FP8 throughput at completely different enter/output size combos
Mixtures: BS=32 for Llama 3.1 8B and BS=64 for Llama-3.1-Minitron 4B fashions. 1x H100 80GB GPU.
Conclusion
Pruning and classical data distillation is a extremely cost-effective methodology to progressively receive LLMs of smaller dimension, reaching superior accuracy in comparison with coaching from scratch throughout all domains. It serves as a more practical and data-efficient strategy in comparison with both synthetic-data-style finetuning or pretraining from scratch.
Llama-3.1-Minitron 4B is our first work with the state-of-the-art open-source Llama 3.1 household. To make use of SDG finetuning of Llama-3.1 in NVIDIA NeMo, see the /sdg-law-title-generation pocket book on GitHub.
For extra data, see the next sources:
- Compact Language Fashions by way of Pruning and Data Distillation
- /NVlabs/Minitron GitHub repo
- Llama-3.1-Minitron fashions on Hugging Face:
- Llama-3.1-Minitron-4B-Width-Base
- Llama-3.1-Minitron-4B-Depth-Base
Acknowledgments
This work wouldn’t have been attainable with out contributions from many individuals at NVIDIA. To say just a few of them: Core Staff: Sharath Turuvekere Sreenivas, Saurav Muralidharan, Marcin Chochowski, Raviraj Joshi; Advisors: Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov; Instruction-tuning: Ameya Sunil Mahabaleshwarkar, Hayley Ross, Brandon Rowlett, Oluwatobi Olabiyi, Shizhe Diao, Yoshi Suhara; Datasets: Sanjeev Satheesh, Shengyang Solar, Jiaqi Zeng, Zhilin Wang, Yi Dong, Zihan Liu, Rajarshi Roy, Wei Ping, Makesh Narsimhan Sreedhar, Oleksii Kuchaiev; TRT-LLM: Bobby Chen, James Shen; HF help: Ao Tang, Greg Heinrich; Mannequin optimization: Chenhan Yu; Dialogue and suggestions: Daniel Korzekwa; Weblog publish preparation: Vinh Nguyen, Sharath Turuvekere Sreenivas.