 NVIDIA has introduced the most recent v0.15 launch of NVIDIA TensorRT Mannequin Optimizer, a state-of-the-art quantization toolkit of mannequin optimization strategies together with quantization, sparsity, and pruning. These strategies scale back mannequin complexity and allow downstream inference frameworks like NVIDIA TensorRT-LLM and NVIDIA TensorRT to extra effectively optimize the inference pace of generative AI fashions.
NVIDIA has introduced the most recent v0.15 launch of NVIDIA TensorRT Mannequin Optimizer, a state-of-the-art quantization toolkit of mannequin optimization strategies together with quantization, sparsity, and pruning. These strategies scale back mannequin complexity and allow downstream inference frameworks like NVIDIA TensorRT-LLM and NVIDIA TensorRT to extra effectively optimize the inference pace of generative AI fashions.
This submit outlines a number of the key options and upgrades of current TensorRT Mannequin Optimizer releases, together with cache diffusion, the brand new quantization-aware coaching workflow utilizing NVIDIA NeMo, and QLoRA help.
Cache diffusion
Beforehand, TensorRT Mannequin Optimizer (known as Mannequin Optimizer) supercharged NVIDIA TensorRT to set the bar for Steady Diffusion XL efficiency with its 8-bit post-training quantization (PTQ) approach. To additional democratize quick inference for diffusion fashions, Mannequin Optimizer v0.15 provides help for cache diffusion, which can be utilized with FP8 or INT8 PTQ to additional speed up diffusion fashions at inference time.
Cache diffusion strategies, reminiscent of DeepCache and block caching, optimize inference pace with out the necessity for added coaching by reusing cached outputs from earlier denoising steps. The caching mechanism leverages the intrinsic traits of the reverse denoising means of diffusion fashions the place high-level options between consecutive steps have a major temporal consistency and could be cached and reused. Cache diffusion is appropriate with quite a lot of spine fashions like DiT and UNet, enabling appreciable inference acceleration with out compromising high quality or coaching value.
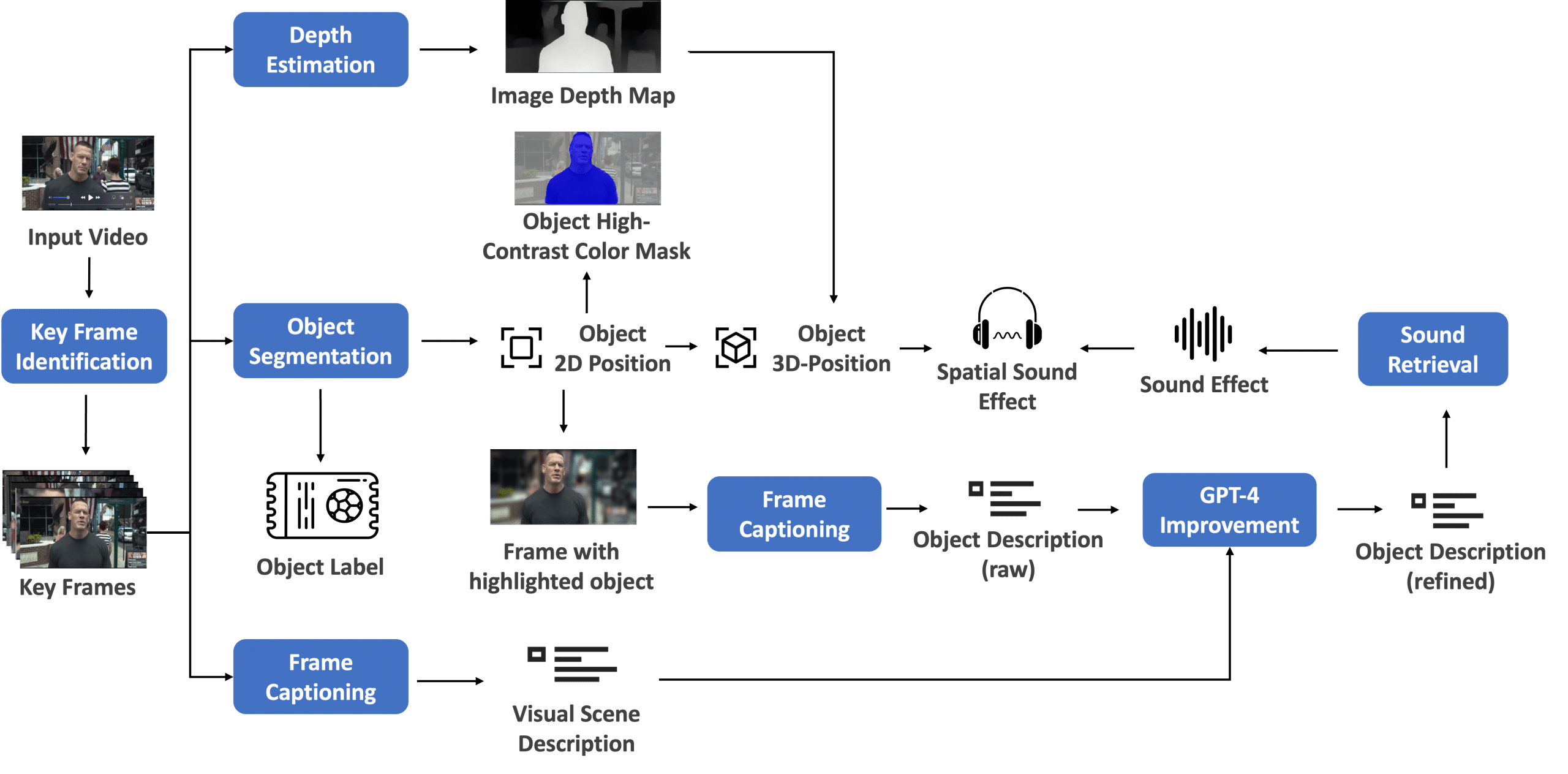
To allow cache diffusion, builders solely want to make use of a single ‘cachify’ occasion in Mannequin Optimizer with the diffusion pipeline. For an in depth instance, see the cache diffusion tutorial pocket book. For an FP16 Steady Diffusion XL (SDXL) on an NVIDIA H100 Tensor Core GPU, enabling cache diffusion in Mannequin Optimizer delivers a 1.67x speedup in photos per second (Determine 1). This speedup will increase when FP8 can also be enabled. Moreover, Mannequin Optimizer permits customers to customise the cache configuration for even quicker inference. Extra diffusion fashions might be supported within the cache diffusion pipeline utilizing TensorRT runtime within the close to future.
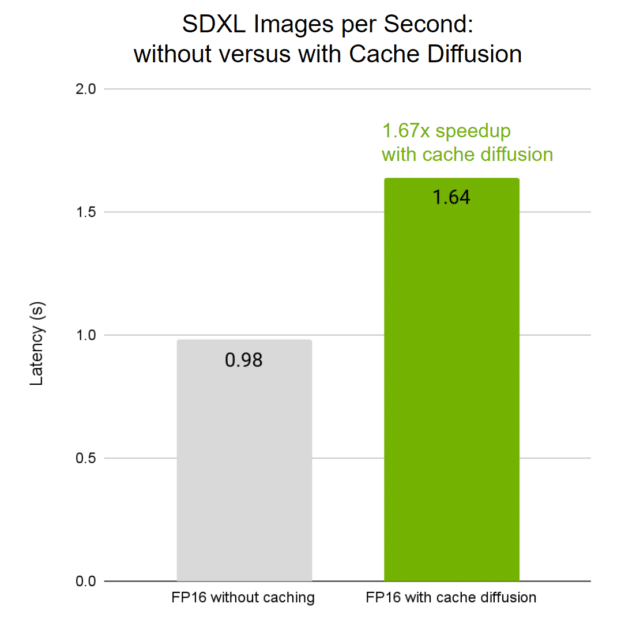
Determine 1. The affect of photos per second (larger is best) of a Steady Diffusion XL when cache diffusion in TensorRT Mannequin Optimizer is enabled
The FP16 with out caching baseline is benchmarked utilizing the Mannequin Optimizer cache diffusion pipeline with caching disabled, moderately than utilizing the demoDiffusion pipeline in TensorRT that has batch measurement limitation, to offer a fairer comparability. NVIDIA H100 80 GB HBM3 GPU; step measurement 30; batch measurement 16; TensorRT v10.2.0; TensorRT Mannequin Optimizer v0.15
Quantization-aware coaching with NVIDIA NeMo
Quantization-aware coaching (QAT) is a method to coach neural networks whereas simulating the consequences of quantization, aiming to get better mannequin accuracy post-quantization. This course of includes computing scaling components throughout coaching and incorporating simulated quantization loss into the fine-tuning course of, making the neural community extra resilient to quantization. In Mannequin Optimizer, QAT makes use of customized CUDA kernels for simulated quantization, attaining decrease precision mannequin weights and activations for environment friendly {hardware} deployment.
A mannequin quantized utilizing the Mannequin Optimizer mtq.quantize() API could be instantly fine-tuned with the unique coaching pipeline. Throughout QAT, the scaling components inside quantizers are frozen and the mannequin weights are fine-tuned. The QAT course of wants a shorter fine-tuning length and it is strongly recommended to make use of small studying charges.
Mannequin Optimizer v0.15 expands QAT integration help from Hugging Face Coach and Megatron to NVIDIA NeMo, an enterprise-grade platform for growing customized generative AI fashions. Mannequin Optimizer now has first-class help for NeMo fashions. To learn to carry out QAT together with your current NeMo coaching pipeline, see the brand new QAT instance within the NeMo GitHub repo. Study extra about QAT.
QLoRA workflow
Quantized Low-Rank Adaptation (QLoRA) is an environment friendly fine-tuning approach to cut back reminiscence utilization and computational complexity throughout mannequin coaching. By combining quantization with Low-Rank Adaptation (LoRA), QLoRA makes LLM fine-tuning extra accessible for builders with restricted {hardware} sources.
Mannequin Optimizer has added help for the QLoRA workflow with NVIDIA NeMo utilizing the NF4 knowledge sort. For particulars in regards to the workflow, seek advice from the NeMo documentation. For a Llama 13B mannequin on the Alpaca dataset, QLoRA can scale back the height reminiscence utilization by 29-51%, relying on the batch measurement, whereas sustaining the identical mannequin accuracy (Determine 2). Observe that QLoRA comes with the trade-offs of longer coaching step time in comparison with LoRA (Desk 1).
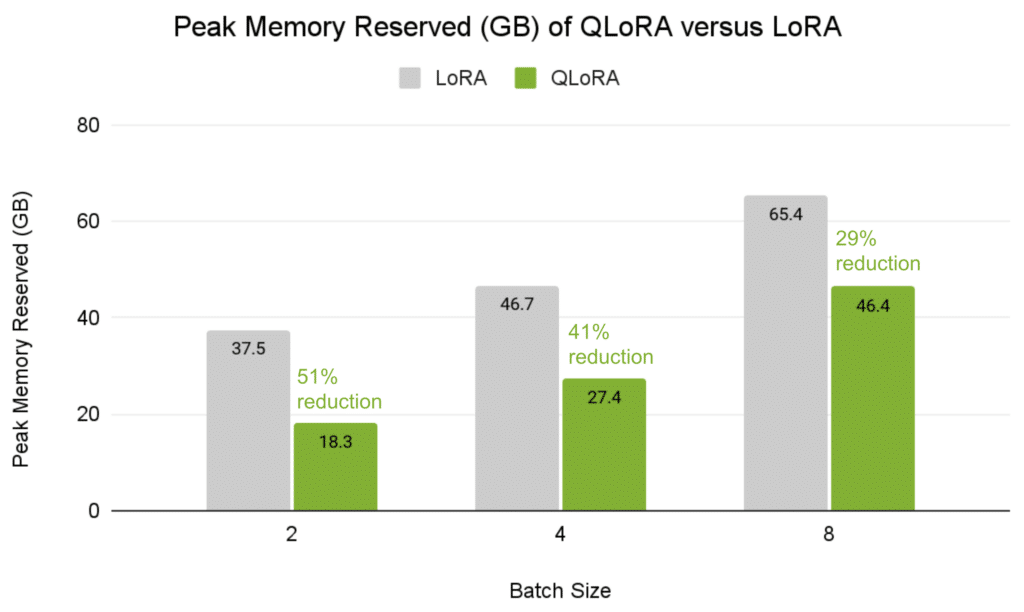
Determine 2. Reminiscence utilization in GB (decrease is best) for fine-tuning Llama 13B on the Alpaca dataset with QLoRA versus LoRA on all layers
NVIDIA H100 GPU; sequence size 512; world batch measurement 256; NeMo 24.07; TensorRT Mannequin Optimizer v0.13
Batch measurement
Time per world batch (s)
LoRA
QLoRA
% Enhance 2 2.7 6.7 148% 4 2.3 4.4 91% 8 2.2 3.2 46%
Desk 1. Coaching efficiency in time per world batch (smaller is best) for a Llama 2 13B utilizing QLoRA versus LoRA on all layers
NVIDIA H100 GPU; sequence size 512; world batch measurement 256; NeMo 24.07; TensorRT Mannequin Optimizer v0.13
Expanded help for AI fashions
TensorRT Mannequin Optimizer has expanded help for a wider suite of well-liked AI fashions, together with Stability.ai Steady Diffusion 3, Google RecurrentGemma, Microsoft Phi-3, Snowflake Arctic 2, and Databricks DBRX. See the instance scripts for tutorials and help matrix for extra particulars.
Get began
NVIDIA TensorRT Mannequin Optimizer affords seamless integration with NVIDIA TensorRT-LLM and TensorRT for deployment. It’s obtainable for set up on PyPI as nvidia-modelopt. Go to NVIDIA/TensorRT-Mannequin-Optimizer on GitHub for instance scripts and recipes for inference optimization. For extra particulars, see the Mannequin Optimizer documentation.
We worth your suggestions on TensorRT Mannequin Optimizer. You probably have recommendations, points, or function requests, open a brand new NVIDIA/TensorRT-Mannequin-Optimizer subject on GitHub. Your enter helps us iterate our quantization toolkit to raised meet your wants.