As massive language fashions (LLMs) proceed to evolve at an unprecedented tempo, enterprises want to construct generative AI-powered purposes that maximize throughput to decrease operational prices and decrease latency to ship superior consumer experiences.
As massive language fashions (LLMs) proceed to evolve at an unprecedented tempo, enterprises want to construct generative AI-powered purposes that maximize throughput to decrease operational prices and decrease latency to ship superior consumer experiences.
This put up discusses the crucial efficiency metrics of throughput and latency for LLMs, exploring their significance and trade-offs between the 2. It additionally appears to be like at how throughput and latency influence the effectivity and consumer expertise of AI purposes, and the way they are often optimized with NVIDIA NIM microservices.
Key metrics for measuring value effectivity
When a consumer sends a request to an LLM, the system processes this request and begins producing a response by outputting a sequence of tokens. There are sometimes a number of requests despatched to the system, which the system tries to course of concurrently to reduce wait time for every request.
Throughput measures the variety of profitable operations per unit of time. Throughput is a crucial measurement for enterprises to find out how nicely they will deal with consumer requests concurrently. For LLMs, throughput is measured by tokens per second. Since tokens are the brand new foreign money, increased throughput can decrease prices and herald income for enterprises.
Moreover, an improved throughput gives a aggressive edge in delivering high-performance purposes that may scale with software program like Kubernetes, resulting in decrease server prices and the power to deal with extra customers.
Latency, the delay earlier than or between knowledge transfers, is measured by time to first token (TTFT) and inter-token latency (ITL). Latency is essential to make sure a clean consumer expertise whereas maximizing total system effectivity.
Determine 1 reveals a mannequin receiving a number of concurrent requests (L1 – Ln) throughout a time period (T_start – T_end), with every line representing the latency for every request. Having extra strains in every row which can be individually shorter equates to increased throughput and decrease latency total.
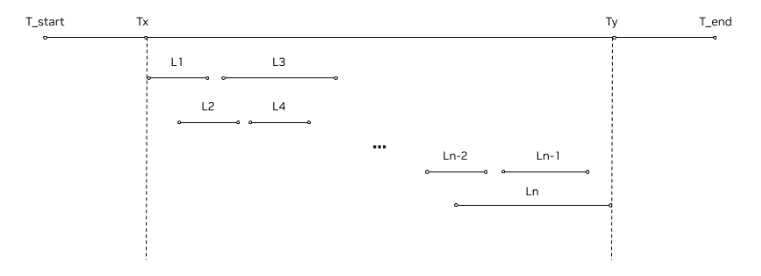
Determine 1. Timeline of request processing on a server from T_start to T_end, with every shorter line phase L1-Ln representing the latency of particular person requests
TTFT measures the time it takes for the mannequin to generate the primary token after receiving a request, indicating how lengthy an finish consumer wants to attend earlier than seeing the primary token. That is important for fast preliminary responses, from buyer assist to e-commerce bots. Most frequently, TTFT ought to be below a couple of seconds; the shorter, the higher, although this imposes constraints on the general system throughput (extra on that within the subsequent part).
ITL refers back to the time interval between producing consecutive tokens, which is important for purposes that require clean and steady textual content era. ITL ought to be lower than human studying pace, to make sure a clean studying expertise.
Determine 2 reveals the mix of those latency benchmarks with the consumer and inference service interplay. The time from the question to the primary generated token is the TTFT and the time between every token is the ITL.
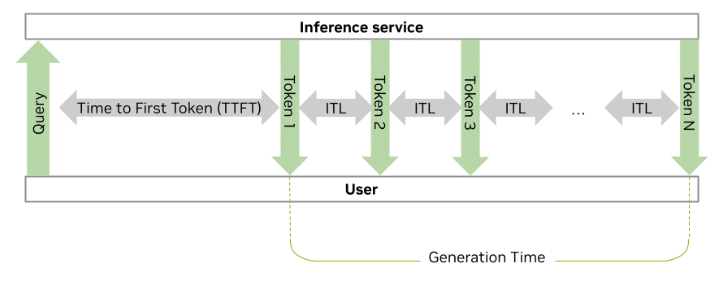
Determine 2. The token era course of in an inference service, highlighting the function of TTFT and ITL
The objective for enterprises is to scale back ITL and TTFT to the extent doable, decreasing latency whereas holding throughput excessive. This ensures the general system is environment friendly and the person consumer’s expertise is clean.
Balancing throughput and latency
The trade-off between throughput and latency is pushed by the variety of concurrent requests and the latency price range, each decided by the appliance’s use case. By dealing with numerous consumer requests concurrently, enterprises can improve throughput; nevertheless, this usually leads to increased latency for every particular person request.
Alternatively, below a set latency price range, which is the suitable quantity of latency the top consumer will tolerate, one can maximize throughput by growing the variety of concurrent requests. Latency price range can pose a constraint for both the TTFT or the end-to-end latency.
Determine 3 illustrates the trade-off between throughput and latency. The y-axis is throughput, and x-axis is latency (TTFT on this case), and the corresponding concurrency is labeled over every marker on the curve. This can be utilized to determine the purpose that maximizes throughput inside a specified latency price range, tailor-made to a particular use case.
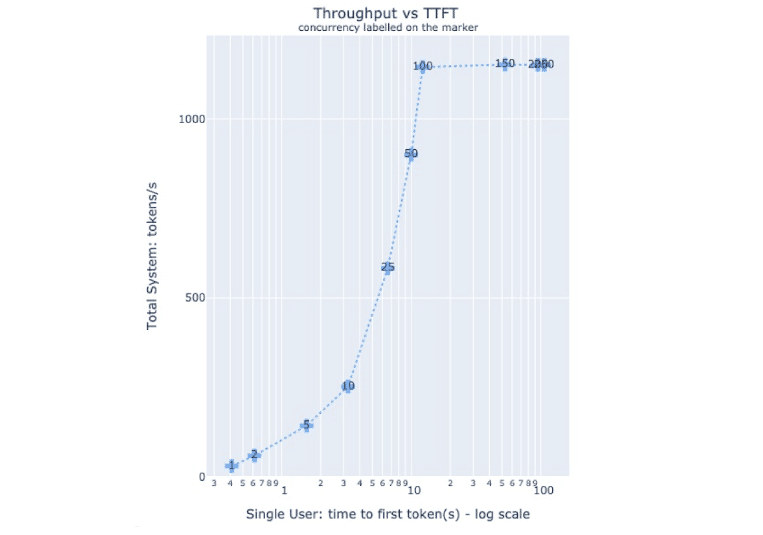
Determine 3. The connection between TTFT and throughput tokens per second
Because the variety of concurrent requests will increase, extra GPUs will be added by standing up a number of cases of the mannequin service. It will maintain the wanted stage of throughput and consumer expertise. For instance, a chatbot dealing with buying requests on Black Friday would want to make use of a number of GPUs to take care of throughput and latency below such peak concurrency.
By specializing in how throughput and latency fluctuate with the variety of concurrent customers. enterprises could make knowledgeable selections on enhancing the effectivity of their AI options based mostly on their use circumstances. This interprets to an ideal steadiness between throughput and latency to keep away from losing sources and decrease server prices.
How NVIDIA NIM optimizes throughput and latency
NVIDIA gives enterprises an optimized resolution to take care of excessive throughput and low latency—NVIDIA NIM. NIM is a set of microservices for optimizing efficiency whereas providing safety, ease of use, and the flexibleness to deploy the fashions anyplace. NIM lowers TCO by delivering low latency and excessive throughput AI inference that scales effectively with infrastructure sources.
With NIM, enterprises can get optimized mannequin efficiency by key methods together with runtime refinement, clever mannequin illustration, and tailor-made throughput and latency profiles. NVIDIA TensorRT-LLM optimizes mannequin efficiency by leveraging parameters equivalent to GPU depend and batch measurement. With NIM, enterprises can have these parameters routinely tuned to greatest go well with their use circumstances to succeed in optimum latency and throughput.
As a part of the NVIDIA AI Enterprise suite of software program, NIM goes by exhaustive tuning to make sure the high-performance configuration for every mannequin. Moreover, methods like Tensor Parallelism (Determine 4) and in-flight batching (IFB) additional enhance throughput and cut back latency by processing a number of requests in parallel and maximizing GPU utilization.
These highly effective optimization methods are extensively accessible to extend efficiency in AI purposes. Moreover, NIM efficiency will improve over time as NVIDIA continues to refine every NIM with every new launch.
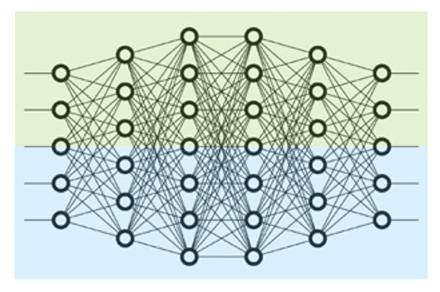
Determine 4. Tensor parallelism reveals how fashions will be sharded to make the most of parallel computing throughout a number of GPUs, growing throughput and minimizing latency by processing requests concurrently
NVIDIA NIM efficiency
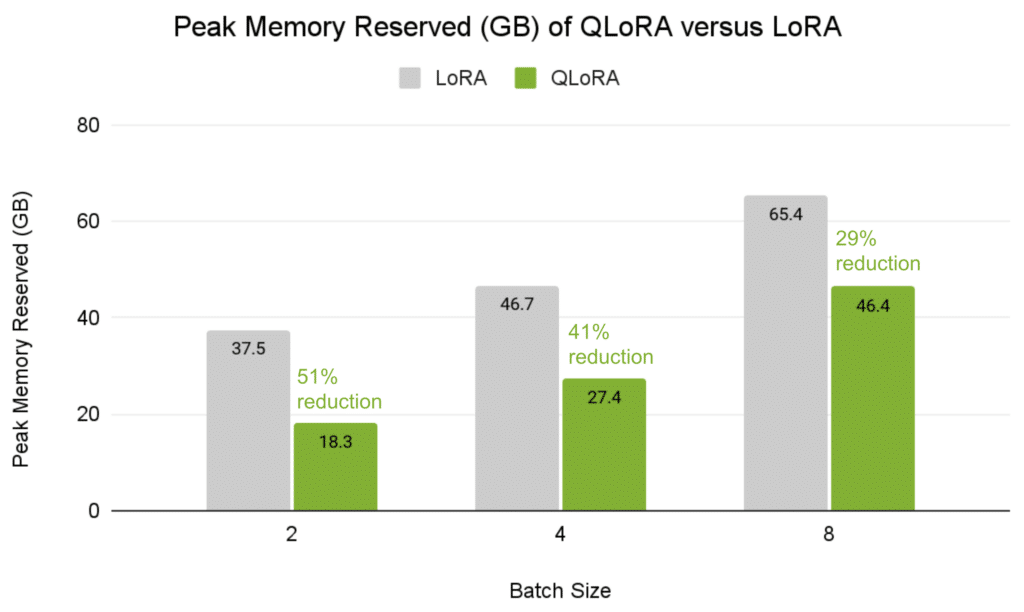
Utilizing NIM, throughput and latency enhance considerably. Particularly, the NVIDIA Llama 3.1 8B Instruct NIM has achieved 2.5x enchancment in throughput, 4x quicker TTFT, and a pair of.2x quicker ITL in comparison with the very best open-source options (Determine 5).
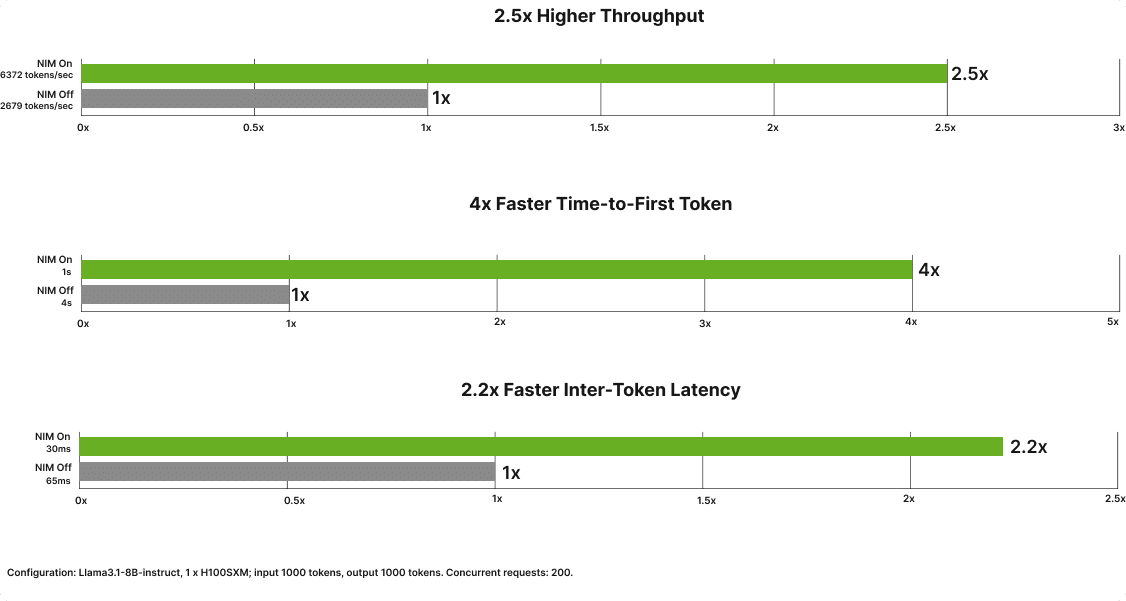
Determine 5. The acceleration enchancment for throughput and latency utilizing Llama 3.1 8B Instruct
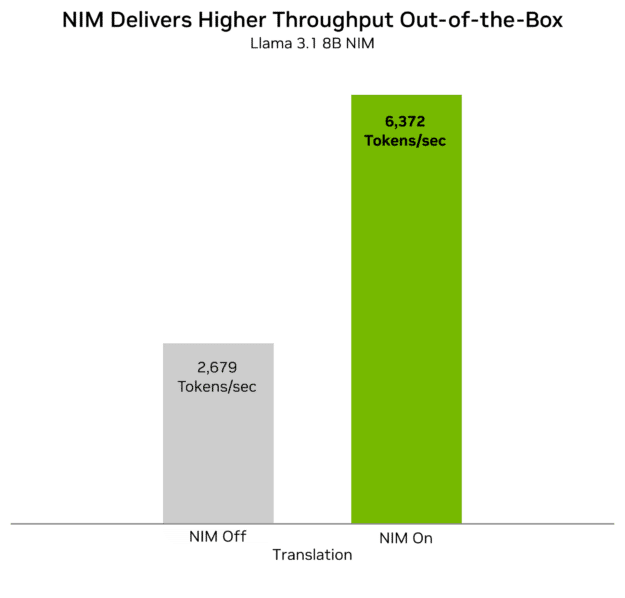
Determine 6 is a dwell demo of NIM On versus NIM Off that reveals real-time chatbot era. NIM On (proper) produces an output 2.4x quicker than NIM Off (left). This speedup with NIM On is supplied by the optimized Tensort-RT LLM and methods beforehand talked about, equivalent to in-flight batching and tensor parallelism.
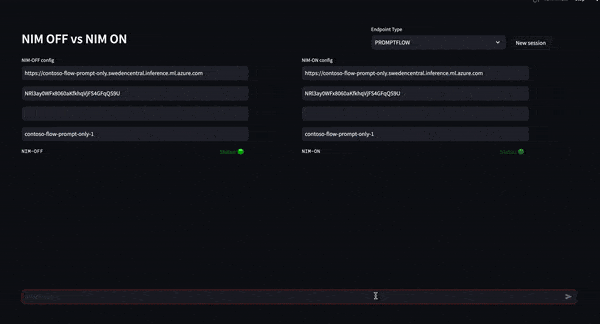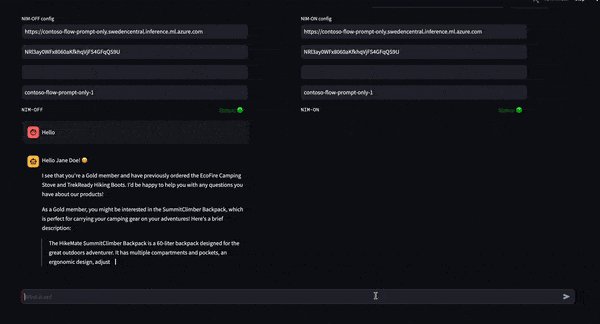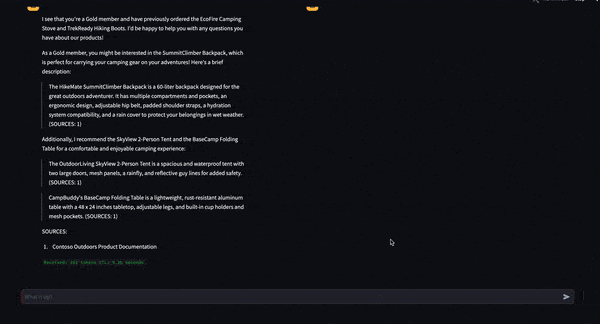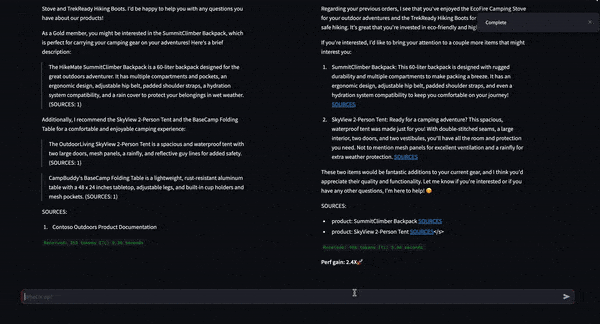
Determine 6. Demo of Mixtral 8x7B working with and with out NIM for a 2.4x ITL acquire with NIM On
Get began
NVIDIA NIM is setting a brand new customary on this planet of enterprise AI by delivering unmatched efficiency, ease of use, and price effectivity. Whether or not you’re seeking to improve customer support, streamline operations, or innovate in your business, NIM gives the sturdy, scalable, and safe resolution you want.
Expertise the excessive throughput and low latency of the Llama 3 70B NIM.
To study extra about benchmarking NIM in your machines, try the NIM LLM Benchmarking Information and NIM documentation.