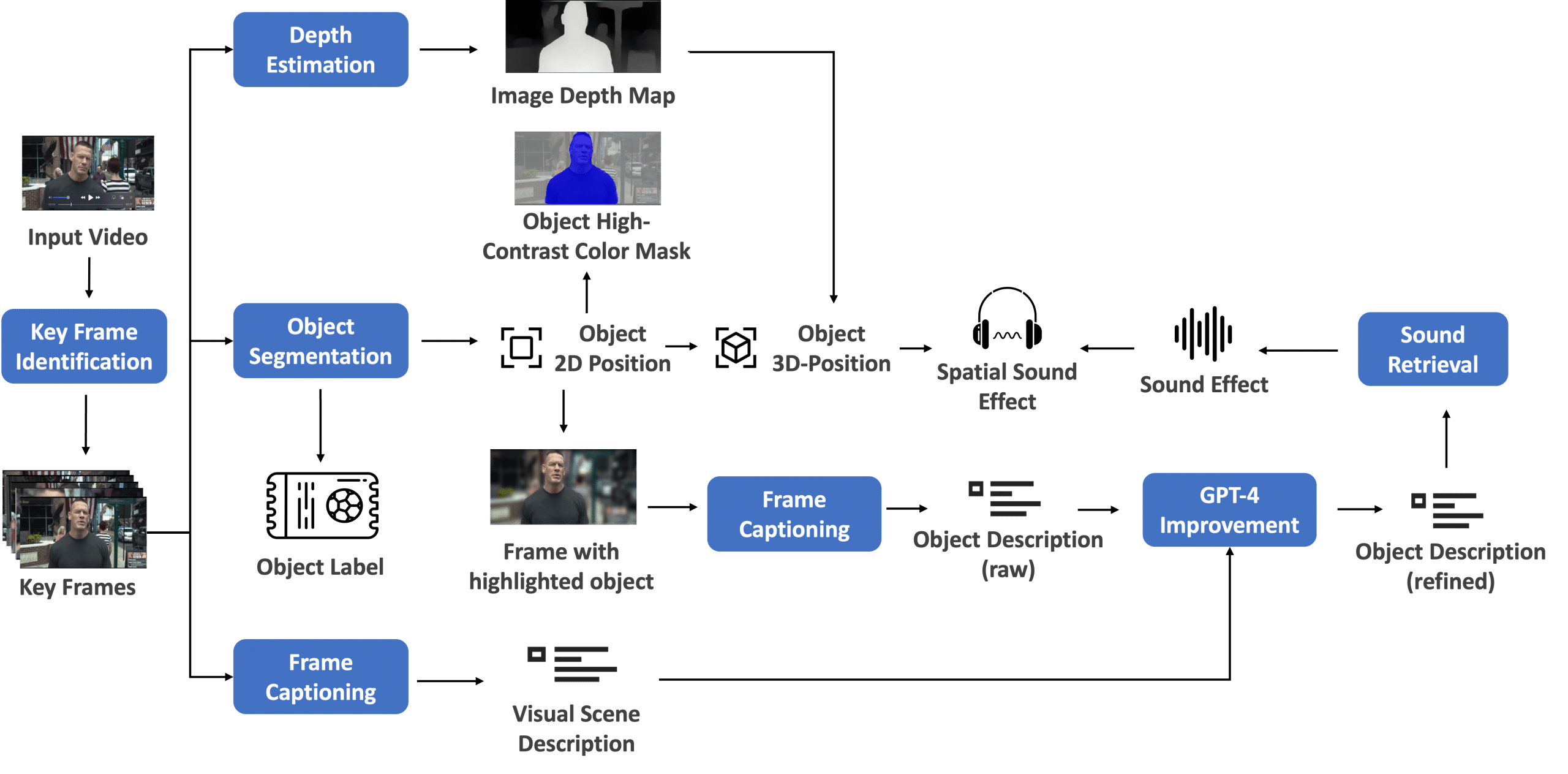
Massive language fashions (LLM) are getting bigger, rising the quantity of compute required to course of inference requests. To fulfill real-time latency necessities for serving at present’s LLMs and accomplish that for as many customers as doable, multi-GPU compute is a should. Low latency improves the person expertise. Excessive throughput reduces the price of service. Each are concurrently vital.
Massive language fashions (LLM) are getting bigger, rising the quantity of compute required to course of inference requests. To fulfill real-time latency necessities for serving at present’s LLMs and accomplish that for as many customers as doable, multi-GPU compute is a should. Low latency improves the person expertise. Excessive throughput reduces the price of service. Each are concurrently vital.
Even when a big mannequin can match within the reminiscence of a single state-of-the-art GPU, the speed at which that GPU can generate tokens relies on the entire compute accessible to course of requests. By combining the compute capabilities of a number of cutting-edge GPUs, real-time person experiences on the newest fashions are doable.
To know the necessity for prime tokens per second, the next GIFs present two eventualities:
- 5 tokens/second: Beneath typical human studying velocity and never real-time.
- 50 tokens/second: A wonderful person expertise.

Determine 1. 5 tokens/second output instance

Determine 2. 50 tokens/second output instance
By utilizing the mixed compute efficiency of a number of GPUs with methods reminiscent of tensor parallelism (TP) to run massive fashions, inference requests could be processed shortly sufficient to allow real-time responses. By fastidiously deciding on the variety of GPUs used to run a mannequin, cloud inference providers also can concurrently optimize each person expertise and price.
For extra details about parallelism methods to stability person expertise, see Demystifying AI Inference Deployments for Trillion Parameter Massive Language Fashions.
Multi-GPU inference is communication-intensive
Multi-GPU TP inference works by splitting the calculation of every mannequin layer throughout two, 4, and even eight GPUs in a server. In idea, two GPUs may run a mannequin 2x quicker, 4 GPUs 4x quicker, and eight GPUs 8x quicker.
Nevertheless, every GPU can’t full their work independently. After every GPU completes the execution of its portion of the mannequin layer, each GPU should ship the outcomes of the calculations to each different GPU, performing an all-to-all discount. Solely then can inference execution proceed to the following mannequin layer.
Minimizing the time spent speaking outcomes between GPUs is crucial, as throughout this communication, Tensor Cores typically stay idle, ready for information to proceed processing.
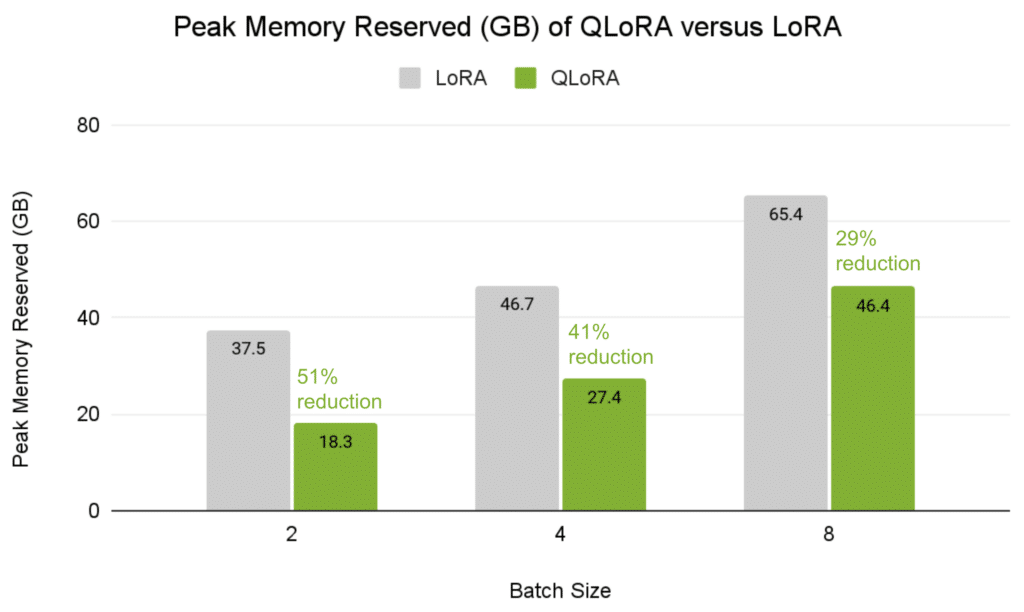
Throughout this communication step, a considerable amount of information should be transferred. A single question to Llama 3.1 70B (8K enter tokens and 256 output tokens) requires that as much as 20 GB of TP synchronization information be transferred from every GPU. As a number of queries are processed in parallel by way of batching to enhance inference throughput, the quantity of knowledge transferred will increase by multiples.
This is the reason a high-bandwidth GPU-to-GPU interconnect is crucial for multi-GPU inference.
NVSwitch is crucial for quick multi-GPU LLM inference
For good multi-GPU scaling, an AI server first requires GPUs with glorious per-GPU interconnect bandwidth. It should additionally present quick connectivity to allow all GPUs to change information with all different GPUs as shortly as doable.
The NVIDIA Hopper Structure GPU can talk at 900 GB/s with fourth-generation NVLink. With the NVSwitch, each NVIDIA Hopper GPU in a server can talk at 900 GB/s with every other NVIDIA Hopper GPU concurrently.
The height charge doesn’t rely upon the variety of GPUs which are speaking. That’s, the NVSwitch is non-blocking. Each NVIDIA HGX H100 and NVIDIA HGX H200 system with eight GPUs options 4 third-generation NVSwitch chips. The entire bidirectional bandwidth of every NVSwitch chip is a staggering 25.6 terabits per second.
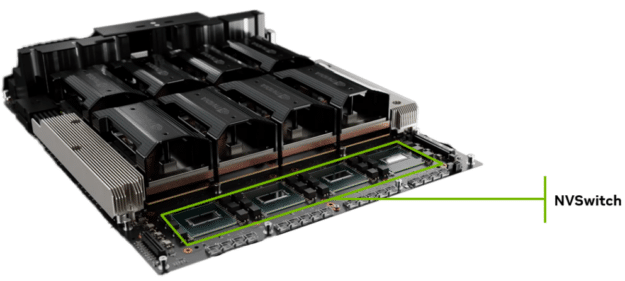
Determine 3. HGX H200 8-GPU with 4 NVIDIA NVSwitch gadgets
For comparability, think about a hypothetical server with eight H200 GPUs with out NVSwitch that as an alternative makes use of point-to-point connections on the server motherboard (Determine 4).
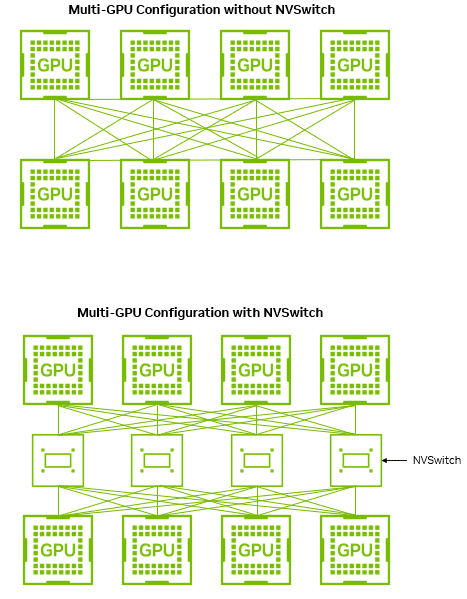
Determine 4. GPU-to-GPU bandwidth with and with out NVSwitch all-to-all change topology
Within the point-to-point design, although it’s a decrease system value with out 4 high-speed switches, every GPU should cut up the identical 900 GB/s connectivity into seven devoted 128 GB/s point-to-point connections, every connecting to one of many different GPUs within the system. Because of this the velocity at which GPUs can talk relies on the variety of GPUs which are speaking.
GPU Rely
Level-to-Level Bandwidth
NVSwitch Bandwidth 2 128 GB/s 900 GB/s 4 3 x 128 GB/s 900 GB/s 8 7 x 128 GB/s 900 GB/s
Desk 1. GPU-to-GPU bandwidth comparability
Desk 1 reveals a GPU-to-GPU bandwidth comparability between GPUs related by way of a point-to-point interconnect and GPUs related with NVSwitch.
For fashions that solely require two GPUs for one of the best stability of person expertise and price, reminiscent of Llama 3.1 70B, a point-to-point structure solely offers 128 GB/s of bandwidth. 20 GB of knowledge would devour 150 ms to carry out simply one of many many all-to-all reductions. With excessive communication overhead, Amdahl’s Regulation limits the speed-up doable with every further GPU.
In the meantime, the system utilizing NVSwitch would offer the complete 900 GB/s of bandwidth, taking solely 22 ms to switch 20 GB, dramatically decreasing the time spent throughout GPU-to-GPU communication. This has a big influence on general inference throughput and person expertise.
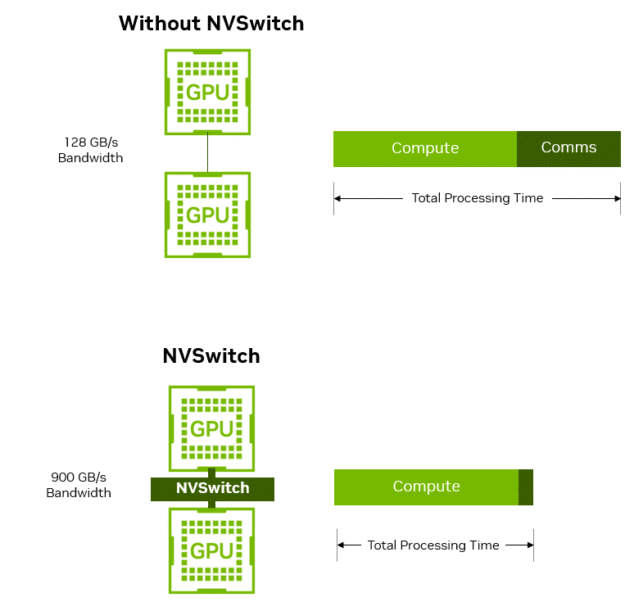
Determine 5. Multi-GPU communication with and with out NVSwitch
Cloud providers typically set mounted response time budgets for mannequin serving, to supply good end-user experiences. This sometimes means with the ability to generate tokens quicker than human studying velocity. To maximise throughput and reduce serving prices, requests are batched as excessive as doable whereas sustaining the response time.
Desk 2 reveals the measured Llama 3.1 70B throughput at varied real-time response time budgets from 30-50 tokens/s/person.
Actual-time Response Finances
tok/s/person
Throughput
tok/s/GPU (batch dimension)
NVSwitch
Profit
Single GPU
TP=1
Level-to-Level
TP=2
NVSwitch
TP=2 30 67 (2) 80 (6) 115 (9)
1.4x 35 Does Not Meet 74 (5) 104 (7)
1.4x 40 Does Not Meet 67 (4) 87 (5)
1.3x 45 Does Not Meet 56 (3) 76 (4)
1.4x 50 Does Not Meet 43 (2) 63 (3)
1.5x
Desk 2. Throughput and NVSwitch profit for Llama 3.1 70B inference at varied real-time person expertise targets with batch sizes
Throughput modeled utilizing inner measurements. H200 GPU, ISL/OSL = 8k/256.
As Desk 2 reveals, a single GPU configuration (TP=1) is challenged to attain real-time efficiency. Splitting the mannequin utilizing tensor parallel throughout two GPUs combines the compute assets of each GPUs to attain excessive throughput throughout a variety of real-time expertise budgets. Actual-time inference throughput on NVIDIA H200 GPUs with TP=2 and NVSwitch is as much as 1.5x higher than a comparable GPU with out NVSwitch.
To point out how NVSwitch advantages eventualities with higher GPU-to-GPU communication visitors, Desk 3 reveals general server throughput at mounted batch sizes. Bigger batch sizes imply that requests from an rising variety of customers could be processed at one time, bettering general server utilization and decreasing value per inference.
Batch Measurement
Throughput
tok/s/GPU
NVSwitch
Profit
Level-to-Level
NVSwitch 1 25 26
1.0x 2 44 47
1.1x 4 66 76
1.2x 8 87 110
1.3x 16 103 142
1.4x 32 112 168
1.5x
Desk 3. Throughput and NVSwitch profit for Llama 3.1 70B inference at varied fixed-batch sizes
Throughput modeled utilizing inner measurements. H200 GPU, TP=2, ISL/OSL = 8K/256.
As batch dimension will increase, GPU-to-GPU visitors will increase, as does the profit offered by NVSwitch in comparison with a point-to-point topology. Nevertheless, even at comparatively modest batch sizes, the positive factors could be vital.
Continued NVLink innovation for trillion-parameter mannequin inference
NVLink and NVSwitch present excessive bandwidth communication between GPUs primarily based on the NVIDIA Hopper structure and supply vital advantages for real-time, cost-effective massive mannequin inference at present.
As mannequin sizes proceed to develop, NVIDIA continues to innovate with each NVLink and NVSwitch to push the boundaries of real-time inference efficiency for even bigger NVLink domains.
The NVIDIA Blackwell structure options fifth-generation NVLink, which doubles per-GPU NVLink speeds to 1,800 GB/s. For Blackwell, a brand new NVSwitch chip and NVLink change trays have additionally been launched to allow even bigger NVLink area sizes.
The NVIDIA GB200 NVL72 system connects 36 NVIDIA Grace CPUs and 72 NVIDIA Blackwell GPUs in a rack-scale design, and with the fifth-generation NVLink, permits all 72 GPUs to behave as a single GPU, enabling 30x quicker real-time trillion-parameter inference in comparison with the prior technology.