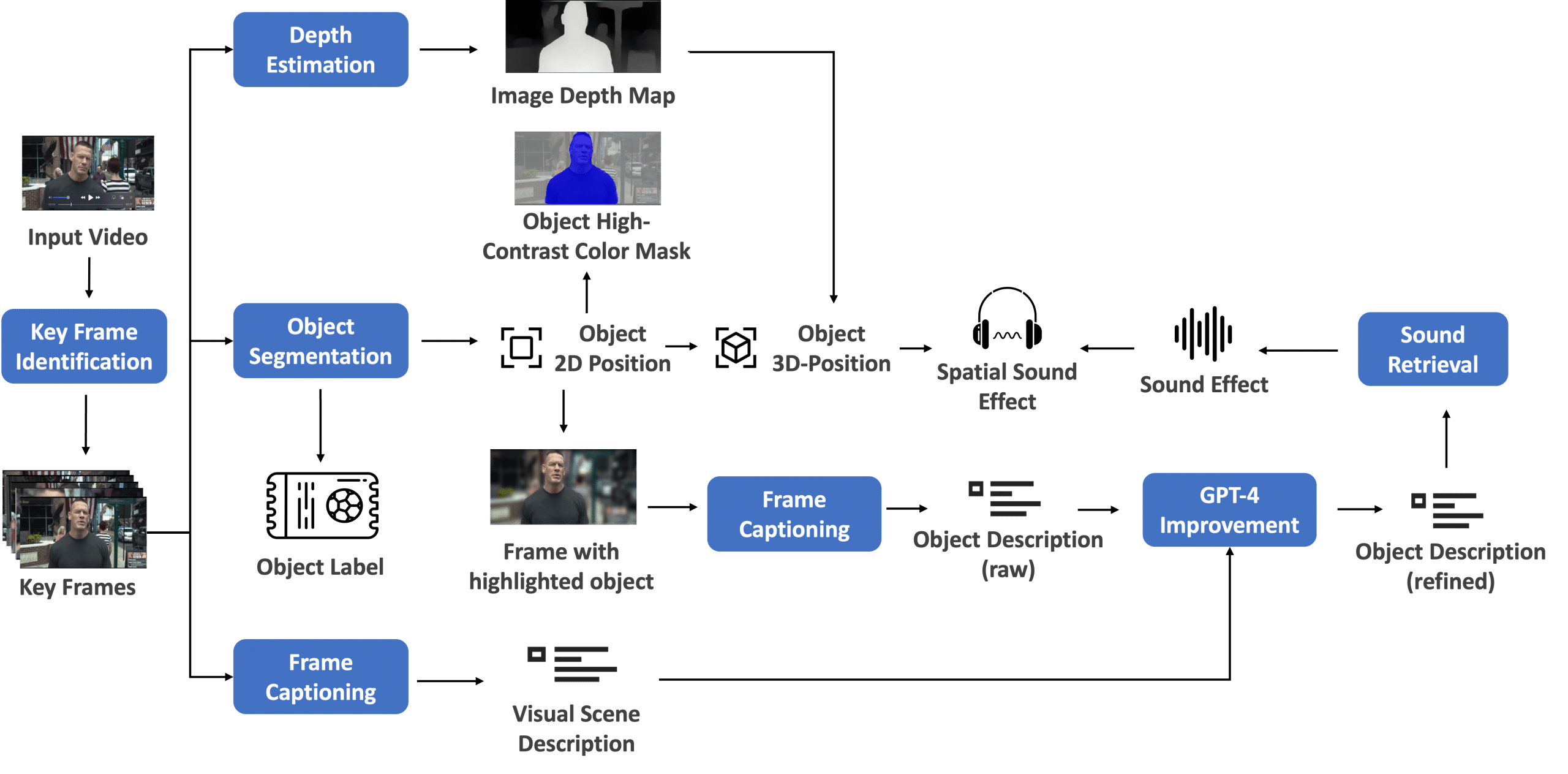
Constructing an efficient automated speech recognition (ASR) mannequin for underrepresented languages presents distinctive challenges as a consequence of restricted information sources.
Constructing an efficient automated speech recognition (ASR) mannequin for underrepresented languages presents distinctive challenges as a consequence of restricted information sources.
On this put up, I talk about one of the best practices for making ready the dataset, configuring the mannequin, and coaching it successfully. I additionally talk about the analysis metrics and the encountered challenges. By following these practices, you may confidentially develop your personal high-quality ASR mannequin for Georgian or another language with restricted information sources.
Discovering and enriching Georgian language information sources
Mozilla Widespread Voice (MCV), an open-source initiative for extra inclusive voice know-how, supplies a various vary of Georgian voice information.
The MCV dataset for Georgian consists of roughly:
- 76.38 hours of validated coaching information
- 19.82 hours of validated growth (dev) information
- 20.46 hours of validated take a look at information.
This validated information totals ~116.6 hours, and continues to be thought of small for coaching a sturdy ASR mannequin. dimension of dataset for the fashions like this begins from 250 hours. For extra info, see Instance: Coaching Esperanto ASR mannequin utilizing Mozilla Widespread Voice Dataset.
To beat this limitation, I included the unvalidated information from the MCV dataset, which has 63.47 hours of information. This unvalidated information might need to be extra correct or clear, so further processing is required to make sure its high quality earlier than utilizing it for coaching. I clarify this further information processing intimately on this put up. All talked about hours of information are after preprocessing.
An attention-grabbing facet of the Georgian language is its unicameral nature, because it doesn’t have distinct uppercase and lowercase letters. This distinctive attribute simplifies textual content normalization, doubtlessly contributing to improved ASR efficiency.
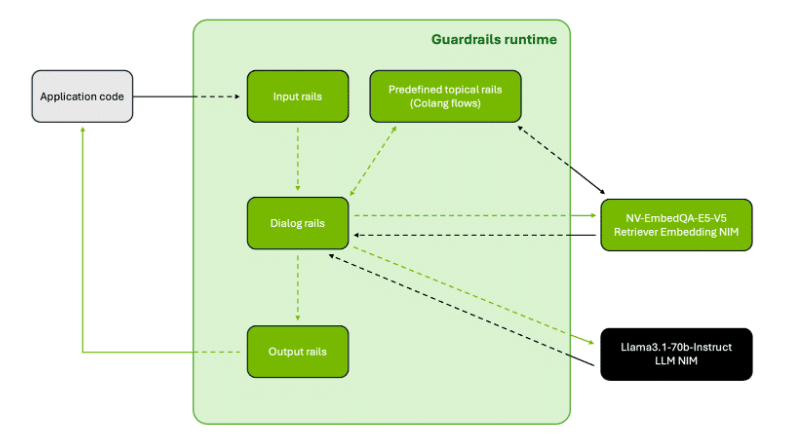
Selecting FastConformer Hybrid Transducer CTC BPE
Harnessing the ability of NVIDIA FastConformer Hybrid Transducer Connectionist Temporal Classification (CTC) and Byte Pair Encoder (BPE) for creating an ASR mannequin gives unparalleled benefits:
- Enhanced pace efficiency: FastConformer is an optimized model of the Conformer mannequin with 8x depthwise-separable convolutional downsampling that reduces the computational complexity.
- Improved accuracy: The mannequin is educated in a multitask setup with joint transducer and CTC decoder loss features bettering speech recognition and transcribing accuracy.
- Robustness: The multitask setup enhances resilience to variations and noise within the enter information.
- Versatility: This answer combines Conformer blocks for capturing long-range dependencies with environment friendly operations appropriate for real-time functions, which permits dealing with a wider vary of ASR duties and ranging degree of complexity and issue.
Effective-tuning mannequin parameters ensures correct transcription and higher consumer experiences even with small datasets.
Constructing Georgian language information for an ASR mannequin
Constructing a sturdy ASR mannequin for the Georgian language requires cautious information preparation and coaching. This part explains how we put together and clear the info to make sure it’s high-quality which incorporates integrating further information sources and making a customized tokenizer for the Georgian language. The part additionally covers the alternative ways to coach the mannequin to realize one of the best outcomes. We give attention to checking and bettering the mannequin all through the method. All steps might be described in additional element under.
- Processing information
- Including information
- Making a tokenizer
- Coaching the mannequin
- Combining information
- Evaluating efficiency
- Averaging checkpoints
- Evaluating the mannequin
Processing information
To create manifest information, use the /NVIDIA/NeMo-speech-data-processor repo. Within the dataset-configs→Georgian→MCV folders, you’ll find a config.yaml file that handles information processing.
Convert information to the NeMo format
Extract and convert all information to the NeMo format mandatory for future processing. In SDP, every processor works sequentially, requiring the NeMo format for the following processors.
Exchange unsupported characters
Sure unsupported characters and punctuation marks are changed with equal supported variations (Desk 1).
Non-supported characters
Alternative ! . … . ; , “:“”;„“-/
area
Lots of areas
area
Desk 1. Unsupported characters alternative schema
Drop non-Georgian information
Take away information that doesn’t include any Georgian letters. That is essential, as unvalidated information usually consists of texts with solely punctuation or empty textual content.
Filter information by the supported alphabet
Drop any information containing symbols not within the supported alphabet, conserving solely information with Georgian letters and supported punctuation marks [?.,].
Filter by characters and phrase incidence
After SDE evaluation, information with an irregular character charge (greater than 18) and phrase charge (0.3<word_rate<2.67) is dropped.
Filter by period
Drop any information that has a period of greater than 18 seconds, as typical audio in MCV is lower than this period.
For extra details about how one can work with NeMo-speech-data-processor, see the /NVIDIA/NeMo-speech-data-processor GitHub repo and the documentation of the Georgian dataset. The next command runs the config.yaml file in SDP:
python predominant.py --config-path=dataset_configs/georgian/mcv/ --config-name=config.yaml
Including information
From the FLEURS dataset, I additionally integrated the next information:
- 3.20 hours of coaching information
- 0.84 hours of growth information
- 1.89 hours of take a look at information
The identical preprocessing steps have been utilized to make sure consistency and high quality. Use the identical config file for FLEURS Georgian information, however obtain it your self.
Making a tokenizer
After information processing, create a tokenizer containing vocabulary. I examined two completely different tokenizers:
- Byte Pair Encoding (BPE) tokenizer by Google
- Phrase Piece Encoding tokenizer for transformers
The BPE tokenizer yielded higher outcomes. Tokenizers are built-in into the NeMo structure, created with the next command:
python <NEMO_ROOT>/scripts/tokenizers/process_asr_text_tokenizer.py
--manifest=<path to coach manifest information, seperated by commas>
OR
--data_file=<path to textual content information, seperated by commas>
--data_root="<output listing>"
--vocab_size=1024
--tokenizer=spe
--no_lower_case
--spe_type=unigram
--spe_character_coverage=1.0
--log
Operating this command generates two folders within the output listing:
text_corpustokenizer_spe_unigram_1024
In the course of the coaching, the trail to the second folder is required.
Coaching the mannequin
The following step is mannequin coaching. I educated the FastConformer hybrid transducer CTC BPE mannequin. The config file is situated within the following folder:
<NEMO_ROOT>/examples/asr/conf/fastconformer/hybrid_transducer_ctc/fastconformer_hybrid_transducer_ctc_bpe.yaml
Begin coaching from the English mannequin checkpoint stt_en_fastconformer_hybrid_large_pc.nemo chosen for its massive dataset and wonderful efficiency. Add the checkpoint to the config file:
title: "FastConformer-Hybrid-Transducer-CTC-BPE" init_from_nemo_model: model0: path: '<path_to_the_checkpoint>/stt_en_fastconformer_hybrid_large_pc.nemo' exclude: ['decoder','joint']
Prepare the mannequin by calling the next command, discovering the one with one of the best efficiency, after which setting the ultimate parameters:
python <NEMO_ROOT>/examples/asr/asr_hybrid_transducer_ctc/speech_to_text_hybrid_rnnt_ctc_bpe.py --config-path=<path to dir of configs> --config-name=<title of config with out .yaml>) mannequin.train_ds.manifest_filepath=<path to coach manifest> mannequin.validation_ds.manifest_filepath=<path to val/take a look at manifest> mannequin.tokenizer.dir=<path to listing of tokenizer> (not full path to the vocab file!)> mannequin.tokenizer.sort=bpe
Combining information
The mannequin was educated with numerous information mixtures:
- MCV-Prepare: 76.28 hours of coaching information
- MCV-Improvement: 19.5 hours
- MCV-Take a look at: 20.4 hours
- MCV-Different (unvalidated information)
- Fleur-Prepare: 3.20 hours
- Fleur- Improvement: 0.84 hours
- Fleur-Take a look at: 1.89 hours
As the proportion ratio between Prepare/Dev/Take a look at is small, in some coaching, I added growth information to the prepare information.
The mixtures of information throughout the coaching embrace the next:
- MCV-Prepare
- MCV-Prepare/Dev
- MCV-Prepare/Dev/Different
- MCV-Prepare/Different
- MCV-Prepare/Dev-Fleur-Prepare/Dev
- MCV-Prepare/Dev/Different-Fleur-Prepare/Dev
Evaluating efficiency
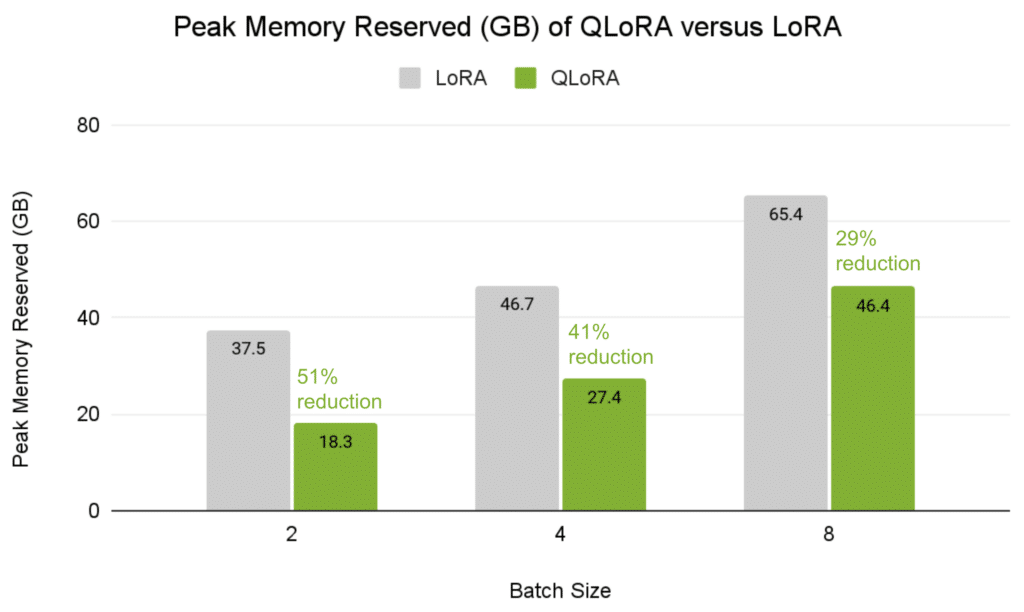
CTC and RNN-T fashions educated on numerous MCV subsets present that incorporating further information (MCV-Prepare/Dev/Different) improves the WER, with decrease values indicating higher efficiency. This highlights the fashions’ robustness when prolonged datasets are used.
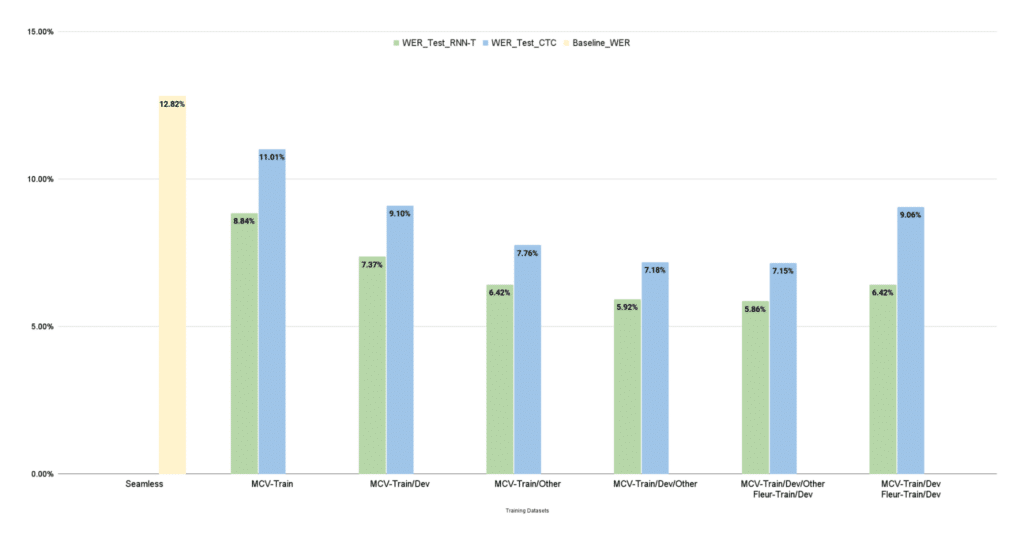
Determine 1. FastConformer efficiency on the Mozilla Widespread Voice take a look at dataset
CTC and RNN-T fashions educated on numerous Mozilla Widespread Voice (MCV) subsets reveal improved WER on the Google FLEURS dataset when further information (MCV-Prepare/Dev/Different) is integrated. Decrease WER values point out higher efficiency, underscoring the fashions’ robustness with prolonged datasets.
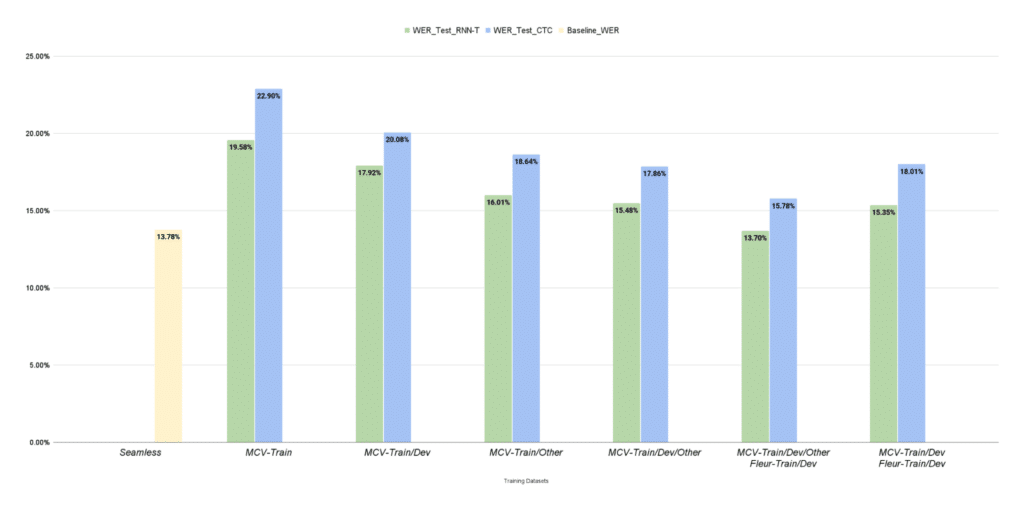
Determine 2. FastConformer mannequin’s efficiency on the FLEURS take a look at dataset
The mannequin was educated with roughly 3.20 hours of FLEURS coaching information, 0.84 hours of growth information, and 1.89 hours of take a look at information, but nonetheless achieved commendable outcomes.
Averaging checkpoints
The NeMo structure lets you common checkpoints saved throughout the coaching to enhance the mannequin’s efficiency, utilizing the next command:
discover . -name '/checkpoints/*.nemo' | grep -v -- "-averaged.nemo" | xargs scripts/checkpoint_averaging/checkpoint_averaging.py <Path to the folder with checkpoints and nemo file>/file.nemo
Finest parameters
Desk 2 lists one of the best parameters for the mannequin with one of the best efficiency dataset, MCV-Prepare/Dev/Different FLEUR-Prepare/Dev.
Parameter
Worth Epochs 150 Precision 32 Tokenizer spe-unigram-bpe Vocabulary dimension 1024 Punctuation ?,. Min studying charge 2e-4 Max studying charge 6e-3 Optimizer Adam Batch dimension 32 Accumulate Grad Batches 4 Variety of GPUs 8
Desk 2. The most effective coaching parameters obtained with MCV-Prepare/Dev/Different FLEUR-Prepare/Dev dataset
Evaluating the mannequin
Roughly 163 hours of coaching information took 18 hours to coach a mannequin on 8 GPUs and one node.
The evaluations think about eventualities with and with out punctuation to comprehensively assess the mannequin’s efficiency.
Following the spectacular outcomes, I educated a FastConformer hybrid transducer CTC BPE streaming mannequin for real-time transcription. This mannequin encompasses a look-behind of 5.6 seconds and latency of 1.04 seconds. I initiated the coaching from an English streaming mannequin checkpoint, utilizing the identical parameters because the beforehand described mannequin. Desk 2 compares the outcomes of two completely different FastConformers, in contrast with these of Seamless and Whisper.
Evaluating with Seamless from MetaAI
FastConformer and FastConformer Streaming with CTC outperformed Seamless and Whisper Giant V3 throughout practically all metrics (phrase error charge (WER), character error charge (CER), and punctuation error charges) on each the Mozilla Widespread Voice and Google FLEURS datasets. Seamless and Whisper don’t assist CTC-WER.
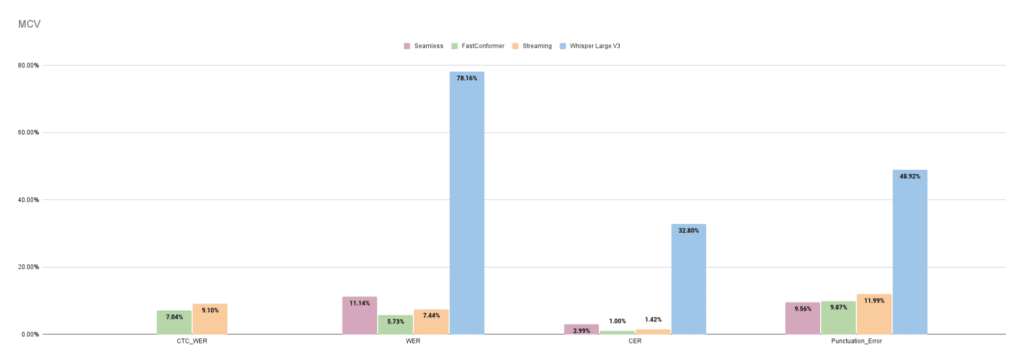
Determine 3. Seamless, FastConformer, FastConformer Streaming, and Whisper Giant V3 efficiency on Mozilla Widespread voice information
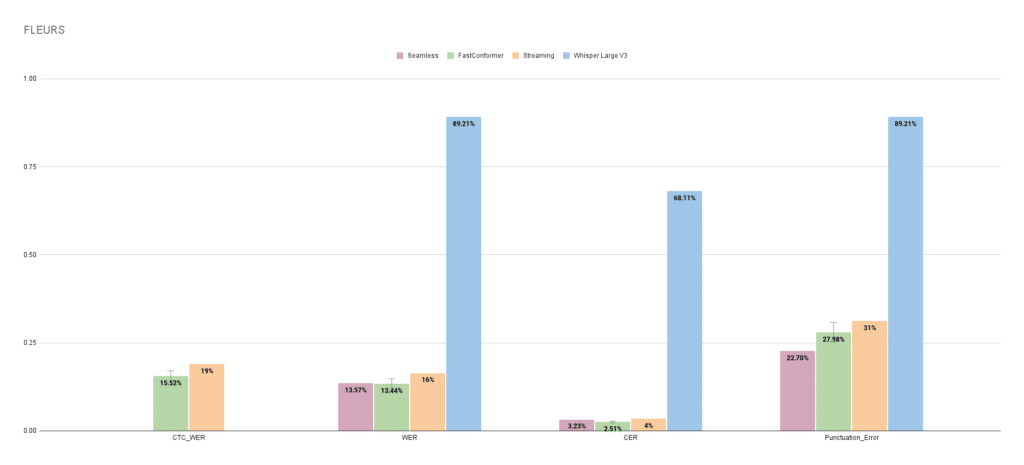
Determine 4. Seamless, FastConformer, FastConformer Streaming, and Whisper Giant V3 efficiency on Google FLEURS voice information
Conclusion
FastConformer stands out as a sophisticated ASR mannequin for the Georgian language, attaining considerably decrease WER and CER in comparison with MetaAI’s Seamless on the MCV dataset and Whisper massive V3 on all datasets. The mannequin’s sturdy structure and efficient information preprocessing drive its spectacular efficiency, making it a dependable selection for real-time speech recognition in underrepresented languages reminiscent of Georgian.
FastConformer’s adaptability to numerous datasets and optimization for resource-constrained environments spotlight its sensible software throughout numerous ASR eventualities. Regardless of being educated with a comparatively small quantity of FLEURS information, FastConformer demonstrates commendable effectivity and robustness.
For these engaged on ASR tasks for low-resource languages, FastConformer is a robust device to think about. Its distinctive efficiency in Georgian ASR suggests its potential for excellence in different languages as nicely.
Uncover FastConformer’s capabilities and elevate your ASR options by integrating this cutting-edge mannequin into your tasks. Share your experiences and ends in the feedback to contribute to the development of ASR know-how.