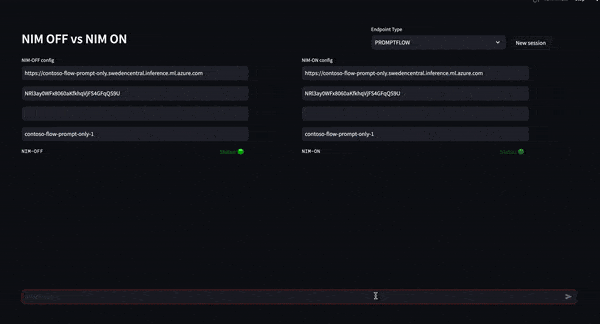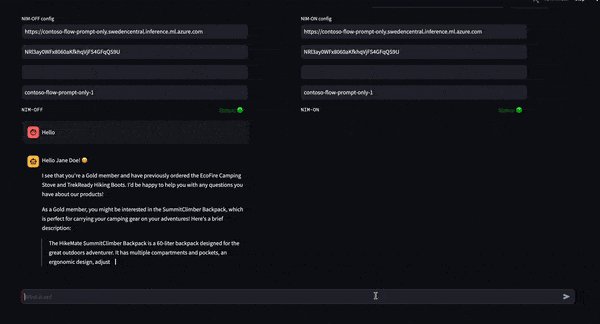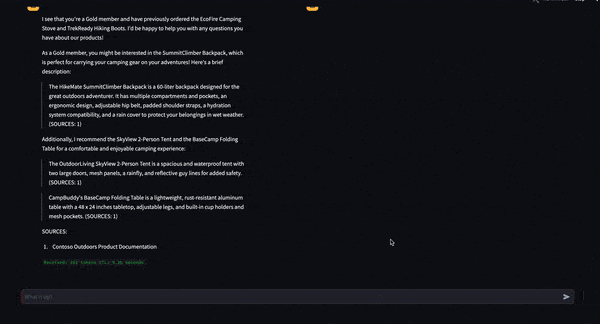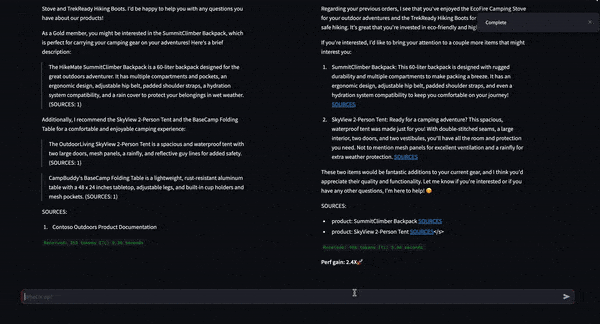
Author has launched two new domain-specific AI fashions, Palmyra-Med 70B and Palmyra-Fin 70B, increasing the capabilities of NVIDIA NIM. These fashions deliver unparalleled accuracy to medical and monetary generative AI functions—outperforming comparable fashions like GPT-4, Med-PaLM 2, and Claude 3.5 Sonnet.
Author has launched two new domain-specific AI fashions, Palmyra-Med 70B and Palmyra-Fin 70B, increasing the capabilities of NVIDIA NIM. These fashions deliver unparalleled accuracy to medical and monetary generative AI functions—outperforming comparable fashions like GPT-4, Med-PaLM 2, and Claude 3.5 Sonnet.
Whereas general-purpose giant language fashions (LLMs) have captured latest headlines, it’s the focused energy of specialised fashions—with their improved accuracy and area information—that’ll reshape complicated, regulated industries like finance and healthcare. Palmyra-Med 70B and Palmyra-Fin 70B are specialised fashions, making them uniquely adept at powering AI workflows in two industries which are recognized for his or her strict regulation and compliance requirements.
Palmyra-Med 70B and Palmyra-Fin 70B are becoming a member of a roster of top-ranking LLMs constructed by Author. These embody the general-purpose mannequin Palmyra-X, Palmyra-Imaginative and prescient for picture evaluation, and plenty of extra. Making Palmyra-Med 70B and Palmyra-Fin 70B out there as NVIDIA NIM microservices improves the composability of the fashions with preconfigured containers that may be deployed to NVIDIA-accelerated structure throughout cloud, knowledge heart, and native platforms.
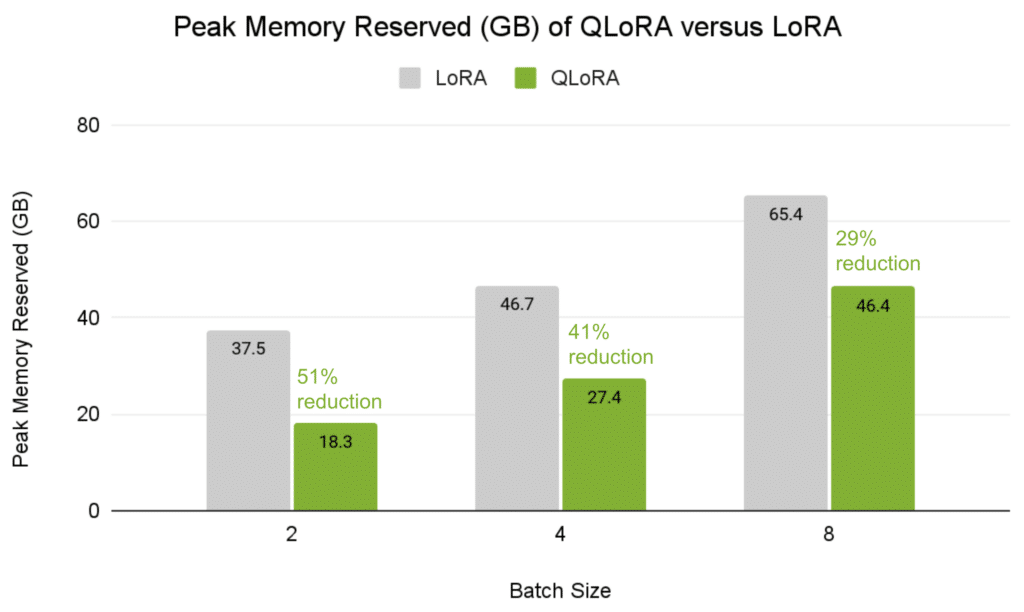
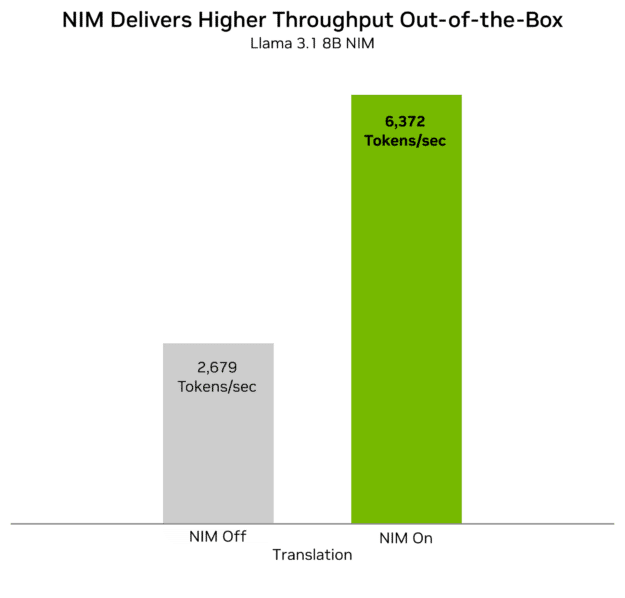
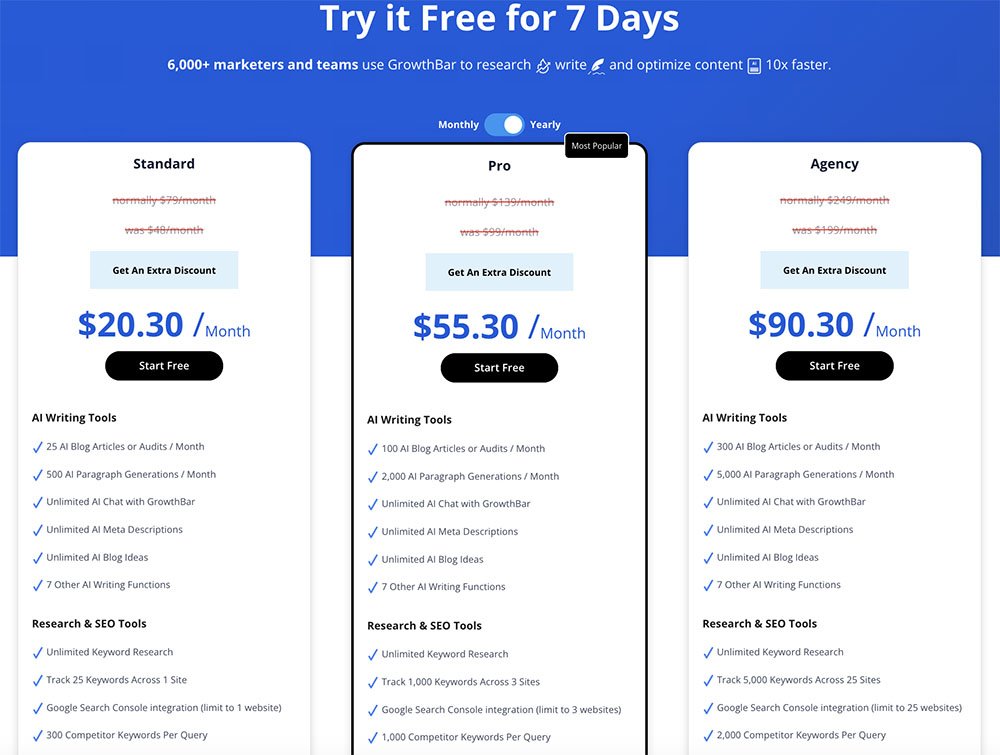
Past facilitating quick deployment, each Palmyra-Med 70B and Palmyra-Fin 70B have seen improved efficiency from NVIDIA AI software program. Optimizations utilizing NVIDIA TensorRT-LLM have diminished inference latency (TTFT) of the fashions by 23% and 30%, respectively, and elevated the speed of token return (TPS) by ~60% for each. The result’s a extra responsive prompting expertise that quickly produces solutions to queries.
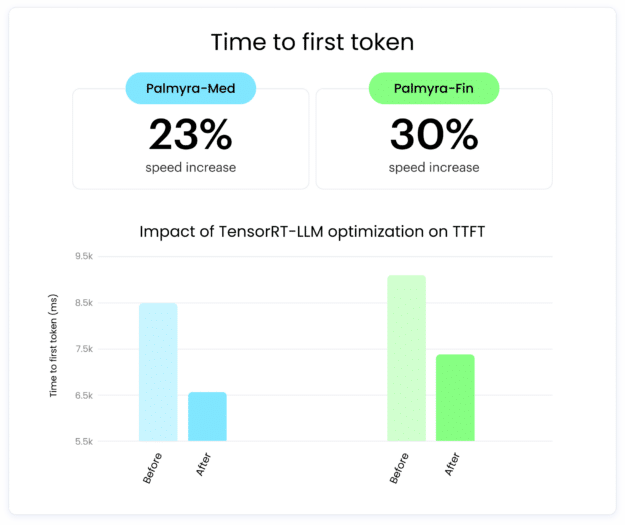
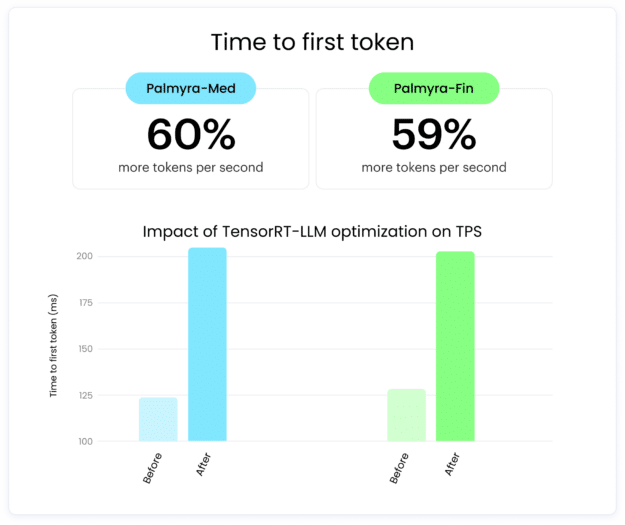
Determine 1. Influence of NVIDIA TensorRT-LLM optimization on TTFT (Ieft) and TPS (proper) for each Palmyra-Med 70B and Palmyra-Fin 70B
Bettering affected person outcomes with record-breaking medical accuracy
Palmyra-Med 70B is the most recent model of our healthcare mannequin and probably the most correct mannequin out there in the marketplace. In our testing, Palmyra-Med 70B averaged 85.9% throughout all medical benchmarks, beating the runner-up, Med-PaLM 2 by near 2 share factors. Med-PaLM 2 solely achieved these outcomes when 5 examples have been offered in comparison with Palmyra’s zero-shot efficiency.
Desk 1 reveals a complete medical Large Multitask Language Understanding (MMLU) benchmark comparability between common fashions. Benchmarks embody MMLU Medical Information, Skilled Drugs, PubMedQA and plenty of extra. See the total record and outcomes.
Palmyra-Med Med-PaLM 2 (5-shot) GPT-4 Gemini 1.0 GPT-3.5 Turbo MMLU Medical Information
90.9 88.3 86 76.7 74.7 MMLU Medical Genetics
94 90 91 75.8 74 MMLU Anatomy
83.7 77.8 80 66.7 72.8 MMLU School Drugs
84.4 80.9 76.9 69.2 64.7 PubMedQA
79.6 79.2 75.2 70.7 72.7 Common*
85.9 84.1 82.8 70.8 66
Desk 1. Complete medical MMLU benchmark comparability of common fashions
*Common efficiency is measured from all 9 assessments
The result’s an correct, dependable mannequin that may assist enhance affected person outcomes and analysis by means of its capacity to deal with complicated medical duties in a spread of disciplines, together with:
- Medical information and anatomy: Reaching scores of 90.9% in MMLU Medical Information and 83.7% in MMLU Anatomy, Palmyra-Med 70B demonstrates a sturdy understanding of scientific procedures and human anatomy. This makes it exceptionally helpful for supporting diagnostic accuracy and remedy planning in medical settings.
- Genetics and faculty medication: Scoring 94.0% in Medical Genetics and 84.4% in School Drugs, the mannequin excels in decoding genetic knowledge and making use of complicated medical information, essential for genetic counseling and medical training.
- Biomedical analysis: With 80% efficiency in PubMedQA, Palmyra-Med 70B proves its functionality to successfully extract and analyze info from biomedical literature, aiding in analysis and evidence-based medical practices.
Author works with a few of the world’s main healthcare firms to assist them enhance affected person outcomes with highly effective generative AI functions. Palmyra-Med 70B is very proficient in a spread of medical use instances together with scientific determination assist, providing evidence-based prognosis ideas and profitable remedy methods. It additionally aids within the improvement and understanding of scientific trial protocols, drug interplay summaries, medical doc era, and way more.
Palmyra-Med 70B empowers builders throughout the medical business to construct new AI apps which are infused with deep medical information and experience.
A strong LLM for finance
Adopting generative AI within the monetary sector comes with its personal distinctive obstacles: prolonged monetary statements, complicated terminology, and nuanced market evaluation. By combining a well-curated set of economic coaching knowledge with customized fine-tuning instruction knowledge, the crew educated a extremely correct monetary LLM that may energy a spread of use instances.
- Monetary development evaluation and forecasts: Inspecting market dynamics and growing forecasts for monetary efficiency.
- Funding evaluation: Producing detailed evaluations of companies, industries, or financial markers.
- Danger analysis: Assessing the potential hazards linked to completely different monetary instruments or approaches.
- Asset allocation technique: Recommending funding mixes tailor-made to particular person danger preferences and monetary aims.
To check the experience of Palmyra-Fin, it was tasked with passing the CFA Degree III examination. The mannequin scored 73% on the multiple-choice part of a CFA Degree III pattern take a look at, making it the primary mannequin that may move the examination. To place this achievement in perspective, passing the CFA Degree III is likely one of the highest distinctions within the funding administration career. The common passing rating during the last 11 years has been 60%, and sometimes lower than half of all take a look at takers obtain a passing rating.
Palmyra-Fin’s efficiency is a stark enchancment over different general-purpose fashions like GPT-4, which have beforehand reported a 33% efficiency on the examination.
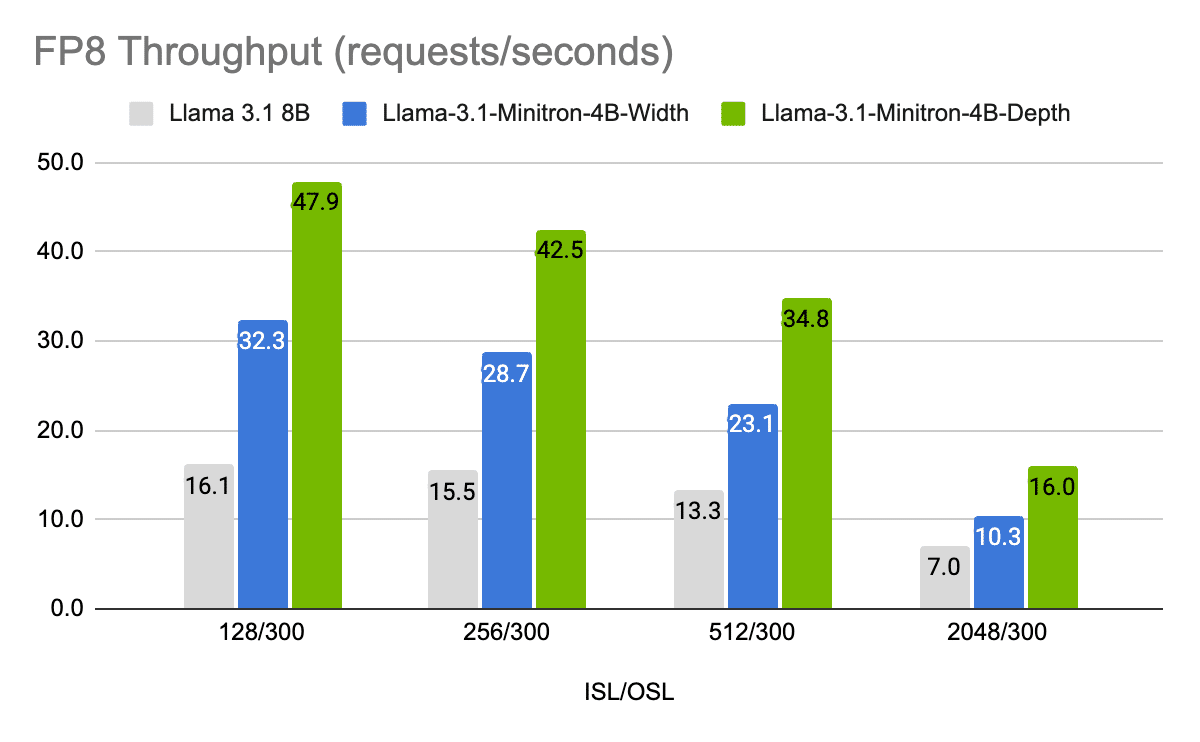
The crew additionally ran Palmyra-Fin by means of the long-fin-eval benchmark take a look at, the place it outperformed common fashions like Claude 3.5 Sonnet, GPT-4o, and Mixtral 8x7B showcasing the mannequin’s capacity to investigate complicated monetary matters.

Determine 2. Palmyra-Fin 70B outperformed different fashions within the long-fin-eval benchmark take a look at
Getting began with Palmyra LLMs
Seeking to the long run, domain-specific LLMs can be on the forefront of AI innovation, remodeling how industries construct specialised AI functions. Author is pioneering this motion by creating fashions like Palmyra-Med 70B and Palmyra-Fin 70B—fashions with deep, sector-specific experience, exceptionally well-suited for enterprise use instances. These focused fashions promise not solely larger accuracy and effectivity, but additionally improved knowledge administration and regulatory compliance.
When you’re constructing an AI utility within the medical or monetary discipline, attempt Palmyra-Med 70B and Palmyra-Fin 70B, accessible by means of the NVIDIA API catalog. For industrial use instances, you may get in contact with the Author crew at gross [email protected].