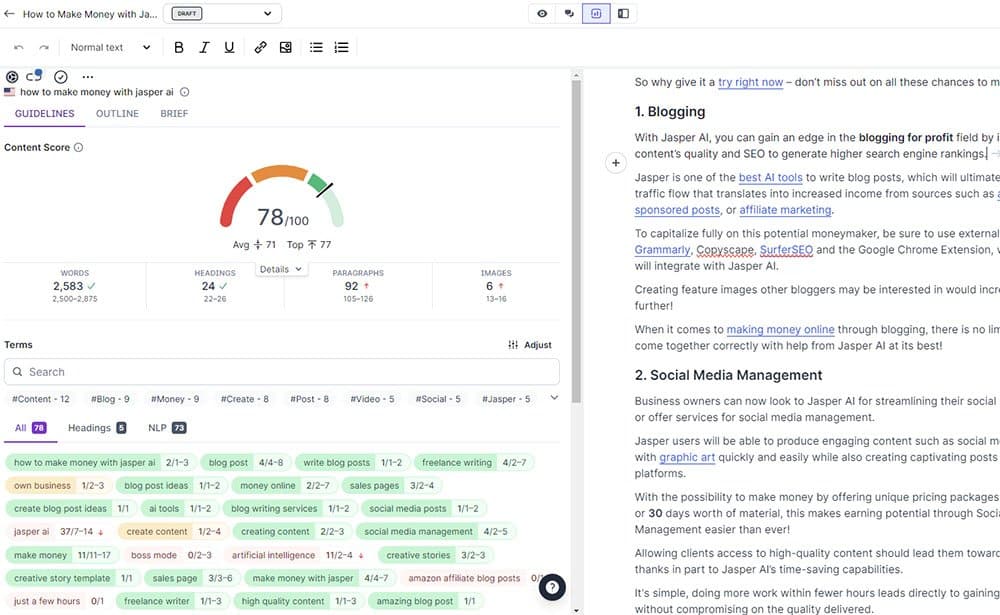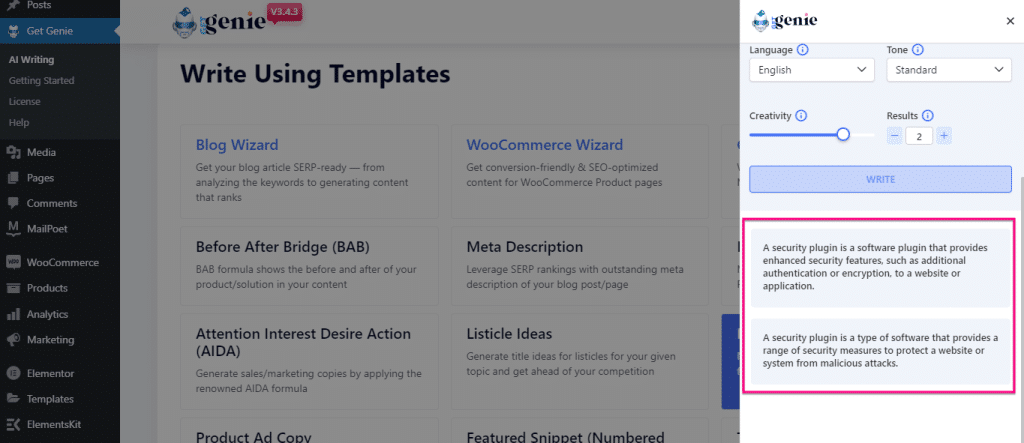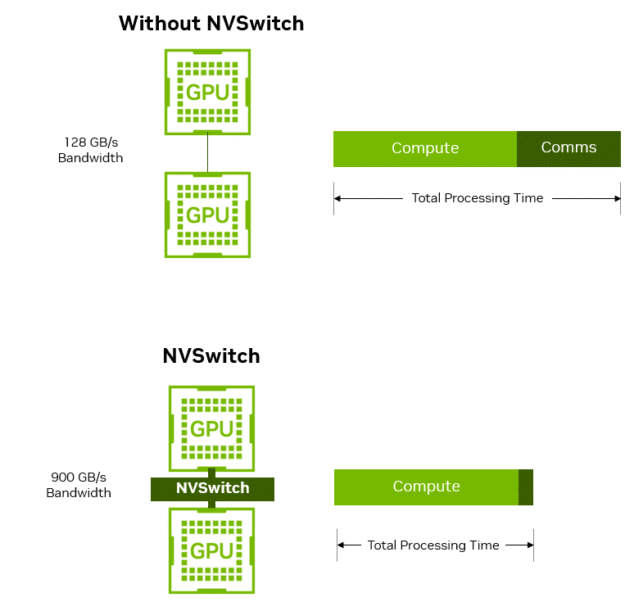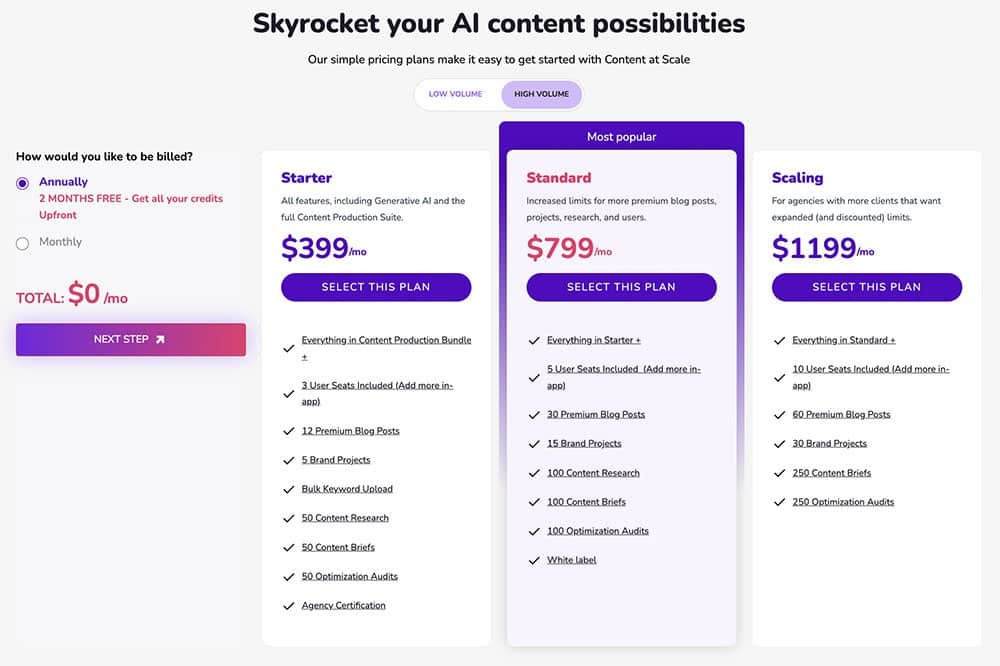
2024 Surfer AI Assessment – The Lengthy Awaited Instrument is Right here! Will it Put Different AI Instruments Out of Enterprise?
As a small enterprise proprietor, I’m all the time searching for methods to enhance effectivity and strategies for writing weblog posts for me to realize higher Google rankings. With greater...
Read more